Izraphail:Т.е. Всю работу делает лопата. Сама идет к яме, сама вонзается в грунт, сама поднимает в грунт и сама отбрасывает его в сторону(аппелируя к вашему примеру).
Нет, конечно, и я писал об этом.
Заявлять что большая работа рейтрейсинга лежит на РТ ядрах, равносильно тому, что сказать что топор делает больше работы чем дровосек.
А как ты объяснишь тогда, такой факт?
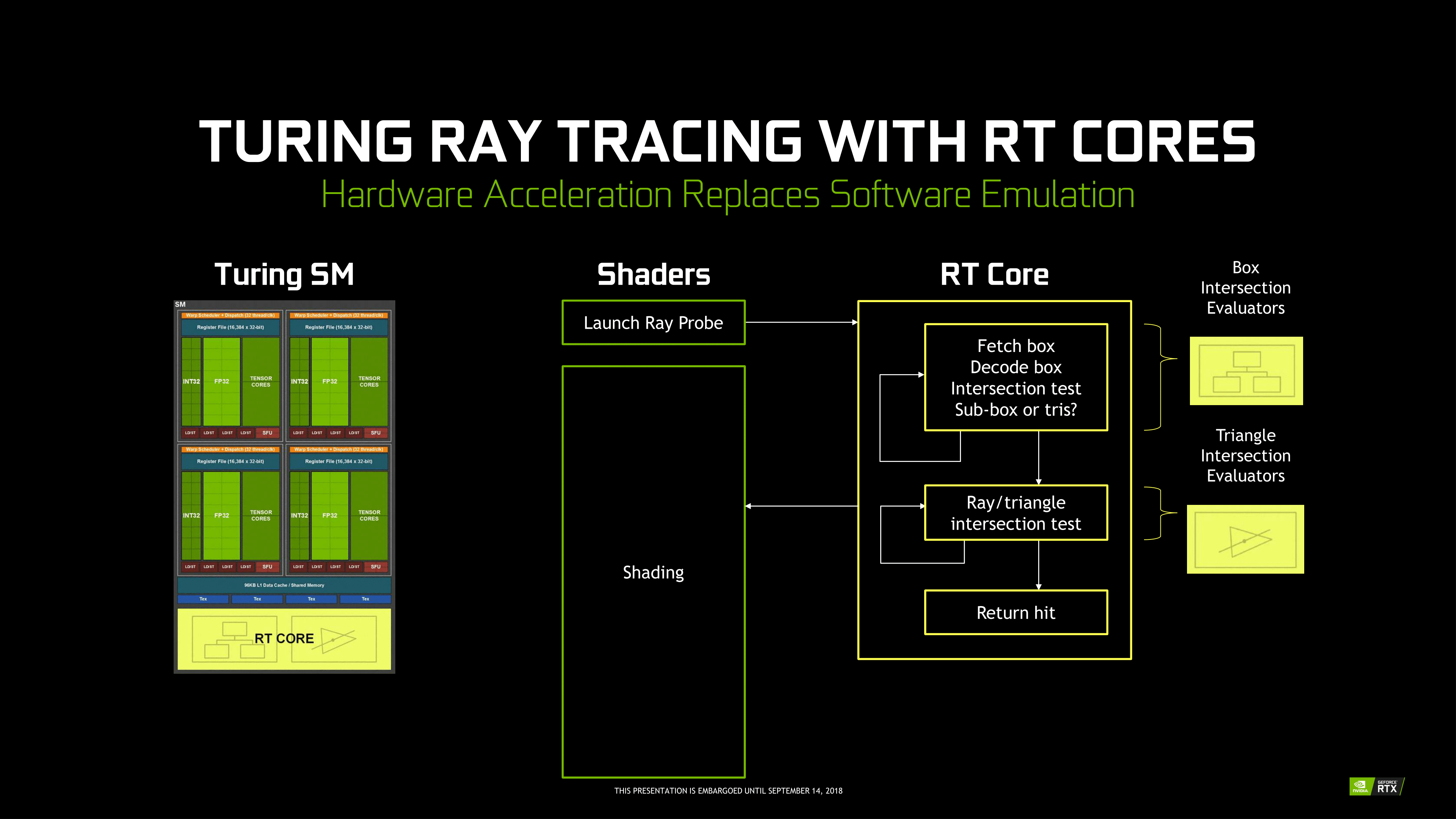
За счет узкой специализации RT-ядра Turing несопоставимо более эффективны в поиске пересечений луча по сравнению с шейдерными ALU. NVIDIA приводит следующие данные: GeForce GTX 1080 Ti, задействовав 10 TFLOPS вычислительной мощности (из доступных 11,3 TFLOPS) исключительно для Ray Tracing, достигает производительности 1,1 млрд лучей/с. GeForce RTX 2080 Ti с помощью 68 RT-ядер превышает отметку в 10 млрд лучей/с, при этом его шейдерные ALU остаются свободны для другой работы.
Так кто же таки даёт такой колоссальный буст в трассировке лучей? Лопата или дровосек, который ей машет?
П.с. и да, Билли, я жду пруфов, о том что я топил за ненужность РТ. Или приступ ЧСВ не позволяет признать тот факт что ты воевал не туда?

Ну, ОК. Про их ненужность заявлял таксист
Wahoo. А ты заявил о том, что недостаточная мощность RT-ядер не может быть бутылочным горлышком в ограничении фпс, т.к.
ОСНОВНУЮ работу по рейтресингу выполняют унифицированные блоки, а не RT-ядра. А из пруфов привел только параметр загрузки ГП на 100%, что ровным счётом не говорит абсолютно ничего.
И потому загрузка ГПУ в потолок, ведь изза ограничения фпс унифицированные шейдерные блоки не простаивают, а начинают майнить биткоины хуану?