
Scoffer
ясно що гомогенний кеш значно краще, тим більше у 3 рази більший
1. швидкість кожної банки 32зчитування+32запис байт в такт, тобто 64*4ГГц*8=2 Терабайт. Звичайно ще внутрішня шина обмежує
2. доступ мінімальний, але середній десь 15 нс, залежить від відстані до банки, зате відразу з 8 портів
Тоді як в Зен2/3 швидкість на зчитування з чіплета була всього 30 Гбайт/с, а якщо врахувати розсинхрон і обмежену швидкість зчитування у свій чіплет, то впаде до 20 Гбайт/с, ну і мінімальна затримка нс 25, тобто 100 тактів. У Zen4 з цим на порядок краще - тут швидкість вже поза 60+ Гбайт/с в кожну сторону на один лінк, ніби, і затримка серйозно впала.
Затримка була б важлива при частому звертанні в кеш чужого чіплета. Але при 32 Мб + 8 МБ Л2 в своєму чіплеті часто звертатись в чужий непотрібно - для зчитування по 32 байта в такт хоча б однієї банки на 4 МБ тре 125 тисяч тактів. Тож тут затримка неважлива, все можна переписувати великими пакетами які нівелюють затримку. На перше місце стає швидкість, а з цим проблема. Якщо б задача була більш-менш порівну розподілена на 2 чіплета і дані не дуже часто вимагали синхронізації, то ніби і всі 64 МБ кешу буде. Але проблема що в іграх якраз є основний потік, який все вирішує, а всі інші потоки беруть його дані, і ясно що потоки в іншому чіплеті будуть тормозити в очікуванні даних. Тому їх і зганяють в один чіплет, напевно, а другий простоює. Хоча, може використовуватись як L4 кеш якщо тре часто обновляти дані. В принципі, на рівні програмування двіжка, чи ігри солідної, могли б врахувати допустиму затримку в доступі, і поставити прапори при компіляції, як роблять для розподілених обчислень, або деякі дані, якщо можна, обраховувати на місці, якщо це швидше ніж отримувати їх з іншого чіплета. Але хто там для ігор париться, видно по Кіберпанку.
Якщо в cpu чіплети введуть зєднання Fabric Link, як зараз в Radeon 7000 причеплені mcm, то швидкість на чіплет зросте в 5-10 раз, а затримка впаде і лише трохи додасть до рівня доступу в L3 кеш
Останні статті і огляди
Новини
Процесори AMD Ryzen 7000X3D для платформи AM5 вийдуть у лютому
-
ronemun
Advanced Member
-
ДядяСаша
Member

- Звідки: Киев
Я згоден, що АМД сам собі не буде конкурентом.Fulkrum: ↑ 05.01.2023 23:55Чиплет у Рязани около 70 мм2, площадь чипа 7600ХТ около 200мм2. Влезет максимум карта уровня 7400ХТ и та упрется в 128 бит ДДР памяти которую прийдется делить с процом.ДядяСаша: ↑ 05.01.2023 12:23Але питання, чому не використати у процах з одним чіплетом площу, яка залишилась від невпаяного другого чіплету для, наприклад, гарного GPU тіпа 7600XT
В итоге те кому нужно играть - купят игровой проц и игровую видуху. Зачем АМД самим себе портить рынок ПК где они и процы и видухи продают? АПУ для консолей они и так миллионами отгружают.
Але, якщо подумати вони взагалі можуть відмовиться випускати бюджетні огризки тіпа 7400/7500, яких треба після релізу продавать ще 10 років.
А якщо, ці чіпчіки закинути в проци то, це буде набагато дешевше чим робить цілу карту, затрати вже закладені в виробництво проца.
Також можна помітити, що доля ринка у АМД сильно просіла і навряд лов-енд щось вирішує в формуванні прибутку від ВК.
А от продаж таких АПУ може бути вкрай вигідно, адже в конкурентів просто нема чим крить(Інтел). Кому треба буде 1630/1650, якщо АПУ буде їх нагинати.
Щодо крупних гравців таких як HP та інші вони можуть від цього тільки виграти.
Все вирішить ціна.
Що до пам'яті, то дуал чанел DDR5 6000= 96ГБ/с, а це майже рівень пропускної здатності 1050ті/RX560, та моєї старої HD 7790.
-
Скоротриндець
Member
- Звідки: Мідгард
відраза від "інтелебоїв" "амудебоїв" "фанів кожанки"... така вже реальність
-
ascord
Member
- Звідки: Нарния
Надо брать 13500
-
waryag
Member

- Звідки: Суми
Проблема пам'яті успішно вирішена в консолях, достатньо не прив'язуватись до актуальної ДДР.ДядяСаша: ↑ 06.01.2023 13:35 Що до пам'яті, то дуал чанел DDR5 6000= 96ГБ/с, а це майже рівень пропускної здатності 1050ті/RX560, та моєї старої HD 7790.
Компактний ПК а-ля xbox X був би бестбаєм навіть з націнкою в 100-200 баксів.
-
Fulkrum
Member

- Звідки: Днепр
Воу воу воу, такие термины, для скофера нужно на пальцах объяснять, он такого не поймет) Еще бы про совместный доступ ядер к разным кэшам с времен Атлонов Х2 напомнил)Mixx: ↑ 06.01.2023 02:06у амд кеш эксклюзивный
Солидная видяха это что то уровня РХ6500? Тут вполне вероятно. Или все же мечты об уровне РХ6700 (ака 7600ХТ?).ronemun: ↑ 06.01.2023 02:27новий IO чіп з солідною відяхою
эм... в видухе как бэ немного больше контроллеров памяти, потому что там шина раза так в 2-3 шире и память немного отличается. То есть тем же контроллером не перекрыть потребности "солидной" видяхи и 8 ядерного проца.ronemun: ↑ 06.01.2023 02:27основні блоки, які займають дуже багато місця, вже присутні в IO чіпі
См. выше - 100мм2 видуху уровня 6500ХТ можно, я об этом не сомневался (хотя это уже на 30% больше чем 8 ядерный чиплет Зен4). разговор был о "солидной" 7600ХТ, а это лишние хотя бы 96-128 бит псп и площадь как 2-3 чиплета.ronemun: ↑ 06.01.2023 02:27APU 6ї версії, 8 ядер Zen3+16МБ кешу займають стільки ж місця як 768 ядер+48текстурників+кеші RDNA2
И они будут паразитировать на контроллере памяти проца? 8 ядер и карта уровня 6700ХТ на 128 битах памяти? Гениальная идея - добавить еще пару каналов памяти, влупить НВМ памяти 8 гиг и продавать 8 ядерный проц с видухой встроенной уровня 7600ХТ по цене 1000+ баксов плюс еще мамку с 4 канальной памятью за 700 баксов. Отбоя от клиентов не будет.ronemun: ↑ 06.01.2023 02:27на 70 мм.кв і на 5нм вміститься всі 1500 ядер, без контролера памяті
Отправлено спустя 3 минуты 18 секунд:
так ринок бюджетных видух существует только для корпоративного сегмента и всяких апдейтов старых компов где выгорел разьем вга)) Не обратили внимания что если раньше анонсы всяких середняков за 100-200 баксов были достаточно громкими событиями, то сейчас просто под шумок переименовывают 8 летнюю карту под новое наименование?ДядяСаша: ↑ 06.01.2023 13:35вони взагалі можуть відмовиться випускати бюджетні огризки тіпа 7400/7500
-
Scoffer
Member

Один фігню зморозив, а інший підхопив.Fulkrum: ↑ 07.01.2023 15:19Воу воу воу, такие термины, для скофера нужно на пальцах объяснять, он такого не поймет) Еще бы про совместный доступ ядер к разным кэшам с времен Атлонов Х2 напомнил)Mixx: ↑ 06.01.2023 02:06у амд кеш эксклюзивный
В сучасних АМД кеш L3 non-inclusive, а не exclusive. Різниця між ними принципова:
- спойлер

- спойлер
- The AMD Family 19h processor implements an up to 32-MB L3 cache (depending on SOC
configuration) that is 16-way set associative and shared by eight cores inside a CPU complex. The L3
is a write-back cache populated by L2 victims. When there is an L3 hit, the line is invalidated from
the L3 if the access was a store. It is invalidated from the L3 if the access was a load and the line was
read by just one core. It stays valid in the L3 if it was a code fetch. It stays valid in the L3 if it was a
load and the line has been read by more than one core. The L3 maintains shadow tags for each L2
cache in the complex. If a core misses in its local L2 and also in the L3, the shadow tags are
consulted. If the shadow tags indicate that the data resides in another L2 within the complex, a cacheto-cache transfer is initiated within the complex. The L3 has an average load-to-use latency of 46
cycles. The non-temporal cache fill hint, indicated with PREFETCHNTA, reduces cache pollution for
data that will only be used once. It is not suitable for cache blocking of small data sets. Lines filled
into the L2 cache with PREFETCHNTA are marked for quicker eviction from the L2, and when
evicted from the L2 are not inserted into the L3.
Тобто ніяка інклюзія чи ексклюзія щодо L3 і близько не гарантується. В залежності від залежностей кеш може поводити себе по-різному. А точніше по одному, він просто вікитимний райт-бек кеш, і тупо не в курсі ні про які ваші інклюзивні політики. А між половинками/четвертинками L3 взагалі якась нова варіація MOESI протоколу.
Зато для L1<->L2 прямо написали що кеш строго інклюзивний і все, без додаткових пояснень, параграф 2.6.2: "This on-die L2 cache is inclusive of the L1 caches in the core."
Відправлено через 4 хвилини 56 секунд:
А от де обіцяли перший на території цієї планети ексклюзивний міжчіповий L3 кеш, так це в процесорі Telum для мейнфрейма IBM Z16. Можете піти купити, і потім з піною доводити як класно шматочки кеша збираються в єдину конструкцію, і навіть будете праві
-
Fulkrum
Member
- Звідки: Днепр
написать три абзаца про инклюзивный и эксклюзивный кэш в ответ на то что ядра имеют доступ в L3 на соседнем чиплете этапять.Scoffer: ↑ 07.01.2023 18:07Один фігню зморозив, а інший підхопив.
Ближе к теме: "AMD says that the bare chiplet can access the stacked L3 cache in the adjacent chiplet".
-
Scoffer
Member
Fulkrum
Знову за своє. Я що десь написав що не мають? Я написав і приклав наглядні тести двох поколінь райзенів що просто мати змогу читати з сусіднього кешу не приносить ніякого профіту в пересічних десктопних завданнях бо затримки читання виходять одного порядку з тими що читати з оперативи. Що так само підтверджується в ігрульках 5800 vs 5900 vs 5800x3d, у котрих у обох останніх нормально сумарного кешу насипано, а практична користь для програми лише в х3d. А ріпер зі своїми 256 метрами сумарного L3 кешу просто всреться всім трьом вищевказаним, хоча здавалось би.
Читай всі літери, а не ті, котрі тобі і амудешним маркетологам подобаються.
З практичної точки зору в десктопних завданнях можна сміливо вважати що на борту 32 метра ефективного, доступного для програми кеша (включно з ріпером, ага, а ніяк не маркетологічно сплюсовані 256). Рідкісні виключення тільки підтверджують правило. Така ціна за чіплетний дизайн проца.
В серверних завданнях при грамотному використанні очевидно все не так, але не про них мова.
Відправлено через 17 хвилин 19 секунд:
Це важливо для програмерів. Вони не можуть просто взяти і написати прогу, котрій сильно-сильно необхідно 64 метра кеша для своєї роботи, оскільки вона на процесорі з 64 метрами розділеного кешу безбожно тупитиме. У них ліміт 32. А на зен2 взагалі був 16
Знову за своє. Я що десь написав що не мають? Я написав і приклав наглядні тести двох поколінь райзенів що просто мати змогу читати з сусіднього кешу не приносить ніякого профіту в пересічних десктопних завданнях бо затримки читання виходять одного порядку з тими що читати з оперативи. Що так само підтверджується в ігрульках 5800 vs 5900 vs 5800x3d, у котрих у обох останніх нормально сумарного кешу насипано, а практична користь для програми лише в х3d. А ріпер зі своїми 256 метрами сумарного L3 кешу просто всреться всім трьом вищевказаним, хоча здавалось би.
Читай всі літери, а не ті, котрі тобі і амудешним маркетологам подобаються.
З практичної точки зору в десктопних завданнях можна сміливо вважати що на борту 32 метра ефективного, доступного для програми кеша (включно з ріпером, ага, а ніяк не маркетологічно сплюсовані 256). Рідкісні виключення тільки підтверджують правило. Така ціна за чіплетний дизайн проца.
В серверних завданнях при грамотному використанні очевидно все не так, але не про них мова.
Відправлено через 17 хвилин 19 секунд:
Це важливо для програмерів. Вони не можуть просто взяти і написати прогу, котрій сильно-сильно необхідно 64 метра кеша для своєї роботи, оскільки вона на процесорі з 64 метрами розділеного кешу безбожно тупитиме. У них ліміт 32. А на зен2 взагалі був 16
-
vmsolver
Member
Не читал обсуждения, но на всякий случай осуждаю 
Просто оставлю картиночку (статья)
Просто оставлю картиночку (статья)
- спойлер
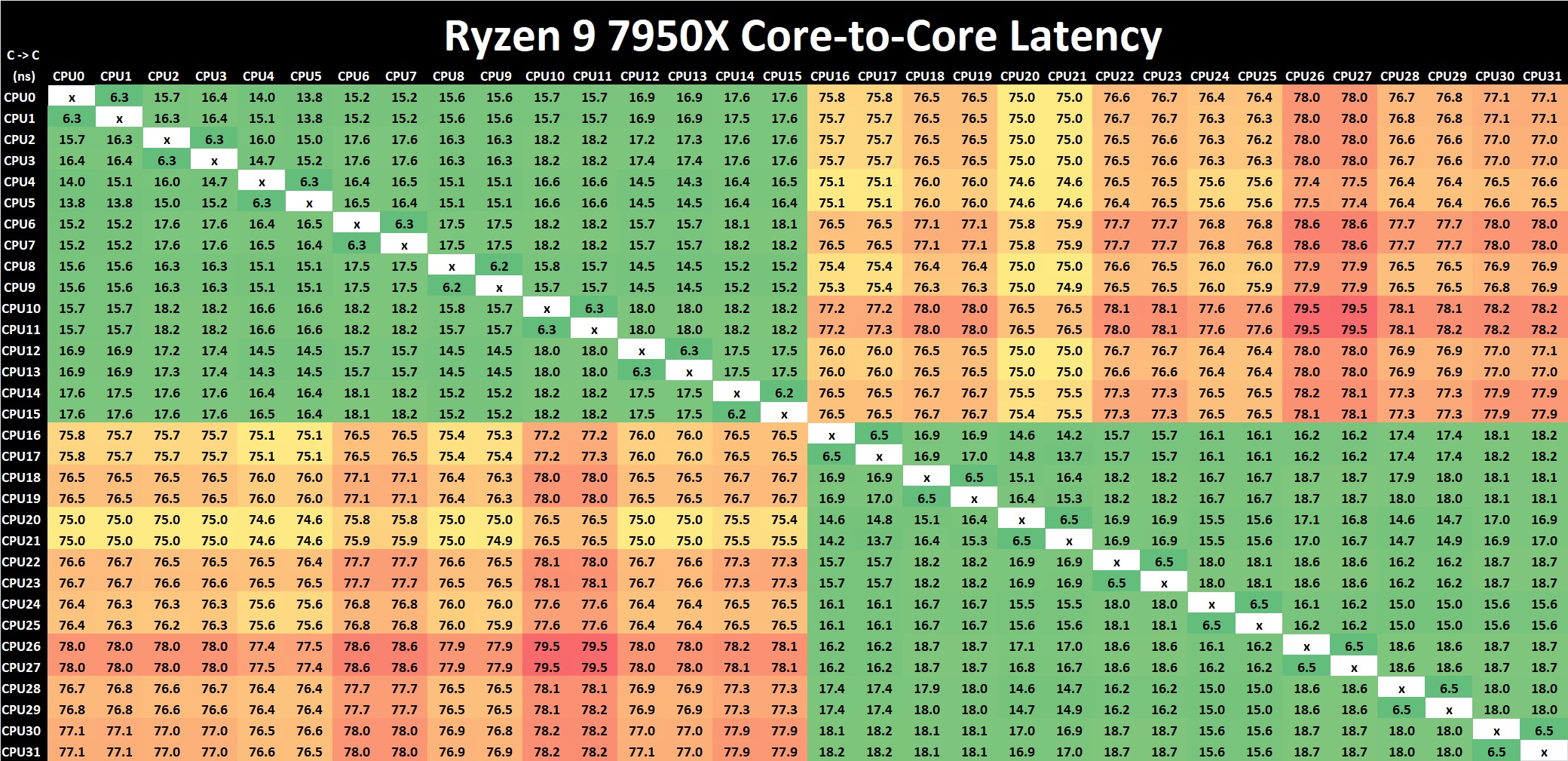
-
Scoffer
Member
vmsolver
Прекрасна картинка, котра ілюстріує рівно те що я сказав. Дані типу є, але щоб дістатись до них потрібно всрати цілих 75-80 наносекунд при тому що в не саму модну оперативу можна сходити за ~65 наносекунд на тому ж самому 7950х:
Але ні, на жаль не можна ігнорувати сусідній L3 і ходити напряму в оперативу, не дивлячись на те що швидше, бо підтримка когерентності, цілісності даних і все таке.
Оце ваші всіма улюблені чіплетики таке творять.
Прекрасна картинка, котра ілюстріує рівно те що я сказав. Дані типу є, але щоб дістатись до них потрібно всрати цілих 75-80 наносекунд при тому що в не саму модну оперативу можна сходити за ~65 наносекунд на тому ж самому 7950х:
- спойлер

Але ні, на жаль не можна ігнорувати сусідній L3 і ходити напряму в оперативу, не дивлячись на те що швидше, бо підтримка когерентності, цілісності даних і все таке.
Оце ваші всіма улюблені чіплетики таке творять.
-
vmsolver
Member
А вообще не совсем, core-to-core latency это немного иное.vmsolver: ↑ 08.01.2023 01:26и посмотрите с какой задержкой они попадут к запрашиваемому ядру.
Что то типа, одно ядро работает с данными, а другое эти данные читает и засекает через какое время ему придёт обновлённое значение, при условии, что первое ядро эти данные изменило. Итак по всем парам ядер измеряют.We measure the latency it takes for a CPU to send a message to another CPU via its cache coherence protocol.
By pinning two threads on two different CPU cores, we can get them to do a bunch of compare-exchange operation, and measure the latency.
Правда, куски кеша L3 это ближе друг к другу не делает (и не должно), но хотя бы корректнее можно оперировать числами в табличке, это быстродействие межядерной синхронизации. Но, можно ли эти данные трактовать как наиболее медленный случай чтения кешированных данных - вопрос открытый.
-
ronemun
Advanced Member
Scoffer
Ну ти ж явно вище 90% форуму що тут сидить - невже ти ще сліпо довіряєш даним Aida64. Там давно такий брє що на голову не налазить. Як в оперативу може бути швидше ніж в кеш L3? як в ядро 7950 сусіднього чіплета може бути 75+ нс, якщо в 5950 було 40+, при тому що в Zen4 IF набагато швидша, що в швидкості, що в частоті, а значить в затримці. В THG навіть в AldelLake і новіше затримка між e-ядрами 55+ нс, що суцільний брєд, адже навіть в Core2 було значно меньше - там L2 спільний. THG давно вже покинули серйозні специ, може прочитати про це в інеті, а Aida малює щось непонятне, яке навіть інтелівські компілятори давно обходять - в них середнє значення для всіх ядер може в рази перевищувати для окремого ядра - хто таке в реальності програмує???
Aida це як вимірювання середньої температури по лікарні - якщо б це було на 4 ядра, як в Zen2 - ще можна було б змовчати, а коли середнє по 2м чіплетам по 8 ядер? Чи як в інтел по 40 ядер? Адже навряд чи при такому великому локальному кешу Постійно будуть звертатись напряму до віддаленого - це нонсенс. Скоріше витіснять мало потрібні дані далі, але звільнять локальний кеш. І витіснення йде великими блоками, тобто маса звернень тупо розмазується в одне, як закладено в суть кешів вже надцять років (навіть шустрий SLC флеш фактично рівний звернення в оперативу - а це більше 5000 нс). І це діє напряму в чіплеті і IO хабі. Навіть в Zen3 було 30 ГБайт/с швидкість від чіплета при затримці між чіплетами менше 15 нс, а при Великому блоці затримка нівелюється, а що тоді в Zen4 з 2-3 рази більшою швидкістю IF. Та при 32 Мбайтах, чи навіть 96, в середньому, кешу про які 96-128 ядер в Epyc можна говорити?
Ну ти ж явно вище 90% форуму що тут сидить - невже ти ще сліпо довіряєш даним Aida64. Там давно такий брє що на голову не налазить. Як в оперативу може бути швидше ніж в кеш L3? як в ядро 7950 сусіднього чіплета може бути 75+ нс, якщо в 5950 було 40+, при тому що в Zen4 IF набагато швидша, що в швидкості, що в частоті, а значить в затримці. В THG навіть в AldelLake і новіше затримка між e-ядрами 55+ нс, що суцільний брєд, адже навіть в Core2 було значно меньше - там L2 спільний. THG давно вже покинули серйозні специ, може прочитати про це в інеті, а Aida малює щось непонятне, яке навіть інтелівські компілятори давно обходять - в них середнє значення для всіх ядер може в рази перевищувати для окремого ядра - хто таке в реальності програмує???
Aida це як вимірювання середньої температури по лікарні - якщо б це було на 4 ядра, як в Zen2 - ще можна було б змовчати, а коли середнє по 2м чіплетам по 8 ядер? Чи як в інтел по 40 ядер? Адже навряд чи при такому великому локальному кешу Постійно будуть звертатись напряму до віддаленого - це нонсенс. Скоріше витіснять мало потрібні дані далі, але звільнять локальний кеш. І витіснення йде великими блоками, тобто маса звернень тупо розмазується в одне, як закладено в суть кешів вже надцять років (навіть шустрий SLC флеш фактично рівний звернення в оперативу - а це більше 5000 нс). І це діє напряму в чіплеті і IO хабі. Навіть в Zen3 було 30 ГБайт/с швидкість від чіплета при затримці між чіплетами менше 15 нс, а при Великому блоці затримка нівелюється, а що тоді в Zen4 з 2-3 рази більшою швидкістю IF. Та при 32 Мбайтах, чи навіть 96, в середньому, кешу про які 96-128 ядер в Epyc можна говорити?
-
Scoffer
Member
ronemun
Не кеш L3, а чужий кеш L3. Для ядра, котре запросило дані, чужий кеш L3 являє собою такий собі інклюзивний недо L4: спочатку відбувається синхронізація з локальним L3 з витісненням "зайвих" даних з локального L3 в оперативу, якщо знадобиться, і лише після дані підуть в локальний L2, а ніяк не напряму. А запис в чужий L3 взагалі проходить в напівасинхроному режимі: синхроно ставиться біт директорії що дані не консистентні і треба б з ними щось зробити, а потім колись там коли дійде до них черга прилітають самі дані. Все це займає до біса багато часу. Це декілька запитів по шині, мінімум два на кожен чих (а скоріше більше), а не один як в випадку з оперативою.
Системам з ссNUMA років так з 25, і вони мають рівно ті ж самі принципово невирішувані проблеми. Взагалі не важливо все на борту одного сокета відбувається, чи в різних.
Я от не розумію з чим ти взагалі сперечаєшся? З тим що наглядні практичні тести включно з в основному цікавлячими людей ігрульками розбивають нісенітниці, котрими затравлюють маркетологи? Що поробиш, таке життя.
Не кеш L3, а чужий кеш L3. Для ядра, котре запросило дані, чужий кеш L3 являє собою такий собі інклюзивний недо L4: спочатку відбувається синхронізація з локальним L3 з витісненням "зайвих" даних з локального L3 в оперативу, якщо знадобиться, і лише після дані підуть в локальний L2, а ніяк не напряму. А запис в чужий L3 взагалі проходить в напівасинхроному режимі: синхроно ставиться біт директорії що дані не консистентні і треба б з ними щось зробити, а потім колись там коли дійде до них черга прилітають самі дані. Все це займає до біса багато часу. Це декілька запитів по шині, мінімум два на кожен чих (а скоріше більше), а не один як в випадку з оперативою.
Системам з ссNUMA років так з 25, і вони мають рівно ті ж самі принципово невирішувані проблеми. Взагалі не важливо все на борту одного сокета відбувається, чи в різних.
Я от не розумію з чим ти взагалі сперечаєшся? З тим що наглядні практичні тести включно з в основному цікавлячими людей ігрульками розбивають нісенітниці, котрими затравлюють маркетологи? Що поробиш, таке життя.
-
ronemun
Advanced Member
Scoffer
та ніхто б тоді багатоядерні серверні проци не купляв би, а тупо скупили би масу десктопних, які на ядро/сокет в рази дешевші, мають вищі частоти/теплопакет, а головне 2 канали памяті на сокет+ 16 PCIe v5/8 Pcie v4 і зєднали би свічами PCIe або копійчаним 100 EDR з затримками <100нс. Спільна оператива робиться дешевим софтом давно, а синхронізація кешів, очевидно, при затримці >75 нс, не має сенсу
Зараз в процах використовуються різні техніки оптимізації завантаження ядер, в т.ч. перенос всього контекту ядра поближче до даних, і якщо дані в іншому чіплеті, то вигідніше і код туди скинути і рахувати паралельно
та ніхто б тоді багатоядерні серверні проци не купляв би, а тупо скупили би масу десктопних, які на ядро/сокет в рази дешевші, мають вищі частоти/теплопакет, а головне 2 канали памяті на сокет+ 16 PCIe v5/8 Pcie v4 і зєднали би свічами PCIe або копійчаним 100 EDR з затримками <100нс. Спільна оператива робиться дешевим софтом давно, а синхронізація кешів, очевидно, при затримці >75 нс, не має сенсу
Зараз в процах використовуються різні техніки оптимізації завантаження ядер, в т.ч. перенос всього контекту ядра поближче до даних, і якщо дані в іншому чіплеті, то вигідніше і код туди скинути і рахувати паралельно
-
Scoffer
Member
ronemun
На серверах люди розуміють як це працює і відповідним чином використовують. Наприклад для віртуалізації вірному налаштуванні, взагалі виключена ситуація коли віртуалка полізе в чужий кеш, там не буде для неї даних. Так само серверні програми, типу СУБД, самі слідкують за своїми потоками і не допускають щоб ці потоки перелізли на ядра з інших нум-ноди, в нормальному режимі роботи.
А десктопні проги по-перше не вміють в нума, а по-друге АМД передбачливо приховала неоднорідну структуру проца, так що вміти ніколи і не будуть. Прогерам ні за що зачепитись, окрім як створювати для своєї програми каталог з усіма процами в природі і мапити потоки до ядер по цьому каталогу. Ну або проводити натурний тест затримок на цільовій системі і мапити по факту тестування
На серверах люди розуміють як це працює і відповідним чином використовують. Наприклад для віртуалізації вірному налаштуванні, взагалі виключена ситуація коли віртуалка полізе в чужий кеш, там не буде для неї даних. Так само серверні програми, типу СУБД, самі слідкують за своїми потоками і не допускають щоб ці потоки перелізли на ядра з інших нум-ноди, в нормальному режимі роботи.
А десктопні проги по-перше не вміють в нума, а по-друге АМД передбачливо приховала неоднорідну структуру проца, так що вміти ніколи і не будуть. Прогерам ні за що зачепитись, окрім як створювати для своєї програми каталог з усіма процами в природі і мапити потоки до ядер по цьому каталогу. Ну або проводити натурний тест затримок на цільовій системі і мапити по факту тестування
-
ronemun
Advanced Member
СУБД і Сервери тут взагалі ні до чого - синхронізація кешів і багатоядерній/сокетній системі обовязкова, свого часу АМД навіть кеш спеціально для цього відділяла. А якщо ядер/потоків більше 32 раніше писали що взагалі немає сенсу робити один комп - синхронізація зїла би всі інтерконекти і всі кеші. Але зараз чомусь так не говорять, хоча проци значно сильніші і на такт і по ядрам. Зараз можна задати при компіляції на скільки має бути відстань в нс між потоками/даними, щоб далеко не перекидувало, це якраз і дозволило оптимізувати в автоматичному режимі що де рахувати, але це вимагало підтримку на апаратному рівні в планувальниках потоків в процах, це ще почали в Броадвелі для серверів. А коли ядра навіть в десктопі мають різну частоту через турбобуст і т.п., то тим більше тре все враховувати, адже навіть багатопочне відеодекодування буде мати розсинхрон потоків, я вже мовчу серйозні речі.
-
Scoffer
Member
ronemun
Ти невірно розумієш синхронізацію кешів. При запису лінії кешу по всім кешам, в яких є ця лінія а то і більша сутність - директорія, виставляється біт когерентності і на тому все. І поки хтось не спробує прочитати дані з місця де локальний кеш в невалідному стані, ніякі дані по шині туди не поїдуть. Це звісно створює деякі накладні витрати в часі для запису. Але не для читання локальних даних.
Що також прекрасно демонструють тести доступу до кешів. З локальними доступами повний порядок.
А спроба засинхронувати всі-всі-всі дані точно призведе до того що оператива виявиться десь на рівні L1 Хоча оно IBM обіцяє в телумі якусь чорму магію на цю тему. Правда за загадковим збігом обставин викладати тести мейнфреймів в публічний доступ прямо заборонено контрактами Дійсно, з чого б?
Хоча оно IBM обіцяє в телумі якусь чорму магію на цю тему. Правда за загадковим збігом обставин викладати тести мейнфреймів в публічний доступ прямо заборонено контрактами Дійсно, з чого б?
Ти невірно розумієш синхронізацію кешів. При запису лінії кешу по всім кешам, в яких є ця лінія а то і більша сутність - директорія, виставляється біт когерентності і на тому все. І поки хтось не спробує прочитати дані з місця де локальний кеш в невалідному стані, ніякі дані по шині туди не поїдуть. Це звісно створює деякі накладні витрати в часі для запису. Але не для читання локальних даних.
Що також прекрасно демонструють тести доступу до кешів. З локальними доступами повний порядок.
А спроба засинхронувати всі-всі-всі дані точно призведе до того що оператива виявиться десь на рівні L1
-
ronemun
Advanced Member
Scoffer
Так, ти правий, ніхто дані не передає, все значно інтелектуальніше. Дані які згідно коду мають спільне використання автоматично синхронізуються по коротшому шляху, в т.ч. код перекидується в ближчі ядра. А коли дані шукаються поза своєю банкою, запит іде по кільцевій шині у інші банки свого чіплета, і також далі по кільцевій шині предається у сусідній чіплет. Звичайно дані про те де що знаходиться може вже перед тим бути синхронізовано і запит піде напряму в потрібну банку
75 нс які представлені вище, це повністю рандомні затримки, яких в природі не існує - такого немає щоб всі ядра і потоки кожен раз запитували дані рандомно - так ніяка шина кільцева + IF не витримає, їх навіть не проектують на такий режим, це шторм якийсь буде. І то 75 нс ще непогано. І в цьому тесті як такого механізму когерентного кешу немає, адже йде звертання в конкретне ядро, а не кеш, де дані можуть бути значно ближче.
Але як видно по іншим підтестам, при інтелектуальній синхронізації, коли дані поступають більш-менш послідовно, все обмежуватиметься шиною подачі даних між чіплетами, а переварити 60 ГБ/с в Zen4 ніяке ядро не зможе, навіть всі 8. Звичайно ще з DRAM дані поступатимуть, і по PCIe. Головне чи сама АМД в десктопний ІО хаб нормально організувала доступ в сусідній чіплет, чи заради навару на 3д кеші "забула" це зробити. Адже якщо б не було користі від кешу сусідніх чіплетів, то Епіки з 2 ядрами на 32 мб кешу взагалі були б глупістю, та ще й за таку ціну на ядро - крім тупого перебору даних в своїх кешах вони нічого не могли б, а якщо б віндовс ще почала ядра перемішувати то взагалі.
Так, ти правий, ніхто дані не передає, все значно інтелектуальніше. Дані які згідно коду мають спільне використання автоматично синхронізуються по коротшому шляху, в т.ч. код перекидується в ближчі ядра. А коли дані шукаються поза своєю банкою, запит іде по кільцевій шині у інші банки свого чіплета, і також далі по кільцевій шині предається у сусідній чіплет. Звичайно дані про те де що знаходиться може вже перед тим бути синхронізовано і запит піде напряму в потрібну банку
75 нс які представлені вище, це повністю рандомні затримки, яких в природі не існує - такого немає щоб всі ядра і потоки кожен раз запитували дані рандомно - так ніяка шина кільцева + IF не витримає, їх навіть не проектують на такий режим, це шторм якийсь буде. І то 75 нс ще непогано. І в цьому тесті як такого механізму когерентного кешу немає, адже йде звертання в конкретне ядро, а не кеш, де дані можуть бути значно ближче.
Але як видно по іншим підтестам, при інтелектуальній синхронізації, коли дані поступають більш-менш послідовно, все обмежуватиметься шиною подачі даних між чіплетами, а переварити 60 ГБ/с в Zen4 ніяке ядро не зможе, навіть всі 8. Звичайно ще з DRAM дані поступатимуть, і по PCIe. Головне чи сама АМД в десктопний ІО хаб нормально організувала доступ в сусідній чіплет, чи заради навару на 3д кеші "забула" це зробити. Адже якщо б не було користі від кешу сусідніх чіплетів, то Епіки з 2 ядрами на 32 мб кешу взагалі були б глупістю, та ще й за таку ціну на ядро - крім тупого перебору даних в своїх кешах вони нічого не могли б, а якщо б віндовс ще почала ядра перемішувати то взагалі.
-
Scoffer
Member
Ну а ти бачив щоб хтось колись на них сервера збирав?ronemun: ↑ 09.01.2023 03:02Епіки з 2 ядрами на 32 мб кешу взагалі були б глупістю