
Пропоную обговорити JEDEC затвердила стандарт багатошарової пам’яті HBM4 для майбутніх прискорювачів обчислень
Цікаво, чому її не використовують у ноутах замість lpddr6?
Останні статті і огляди
Новини
JEDEC затвердила стандарт багатошарової пам’яті HBM4 для майбутніх прискорювачів обчислень
-
yurius_r
Member
-
Scoffer
Member

yurius_r
Окрім того що HBM в багато-багато раз дорожче, в неменше раз більш прожерлива, і, до того ж, має не самі видатні навіть за мірками lpddr затримки? Та немає ніяких причин
Окрім того що HBM в багато-багато раз дорожче, в неменше раз більш прожерлива, і, до того ж, має не самі видатні навіть за мірками lpddr затримки? Та немає ніяких причин
-
vmsolver
Member

В ноутах нет таких GPU, чтобы такая память была реально нужна и оправдана по цене.yurius_r: ↑ 17.04.2025 16:28Цікаво, чому її не використовують у ноутах замість lpddr6?
-
yurius_r
Member
vmsolver
Я не про GPU, яж написав про lpddr
Scoffer
А трошки більше інфо в цифрах? А то виявиться що "багато-багато" це 10%, а пропускну здатність на чіп там таку можна зробити, що можливо ті затримки і не вирішать нічого, особливо при інтегрованих GPU або системах тіпу Ryzen AI Max
Я не про GPU, яж написав про lpddr
Scoffer
А трошки більше інфо в цифрах? А то виявиться що "багато-багато" це 10%, а пропускну здатність на чіп там таку можна зробити, що можливо ті затримки і не вирішать нічого, особливо при інтегрованих GPU або системах тіпу Ryzen AI Max
-
ronemun
Advanced Member
yurius_r
на LikedIn спеціаліст Samsung з виробництва DRAM викладав дані про обєм памяті який вміщається на 1ну 300 мм пластину, в ТБайтах
Так HBM3 виходить в 3+ раз меньше ніж DDR5. Тому і ціна пластини в 3+ раз дорожча за той же обєм. Це все через широку шину - 1кбіт. HBM4 буде ще дорожча - шина 2кбіт
Інші перешкоди:
0. HBM память це 1-2 тісячі біт, 3-5 тисячі контактів, всі розміщені на площі 3 мм від краю кристалу, і для приєднання до проца вимагає кремнієвий інтерпозер, по суті чіп-посередник з доріжками на техпроцесі 22нм, і відповідний контролер і контакти мають бути в процесорі. Сама процедура приєднання точна і дорога без можливості ремонту.
1. HBM память в жахливому дефіциті - вона життєво важлива для AI, а зараз черга на прискорювачі на 3 роки вперед і 10+ міліонів штук (тільки Маск вже замовив пару міліонів), тож чіпів максимального обєму тре десятки міліонів, а кожен чіп це 12-16 кристалів по 2 Гбайт зєднані в один пакет десятками тисяч TSV зєднань наскрізь
2. По суті память дорога не тільки через обєм чіпа, а в основному через кількість кристалів в упаковці чіпа. Для планок ddr5 DRAM на 256 Гбайт чіпи на 16 Гбайт з 8 кристалів по 2 Гбайт в 5-10 раз дорожчий ніж чіп 4 кристали по 1,5 Гбайт для планок 48 Гбайт чи 8 кристалів по 1 Гбайт для планок 64 Гбайт
3. память максимально дешева лише при дуууже великих партіях закупки. Наприклад Інтел для своїх LunarLake, які продаються відразу з розпаяною LPDDR, незмогла домовитись задешево. Що тоді казати про купівлю HBM - замовляти тре на 300+ міліонів і гроші наперед
взагалі ваша пропозиція має раціональність, зарашні інтегровані відеокарти дуже потужні і могли б теж скористатись з HBM. Але тре навпаки 512 біт, не більше, щоб ціну здешевити. Також якщо рахувати ціну за ГБайт/с то HBM контролер памяті і його інтерфейс займає знааачно меньше місця на кристалі процесора чи APU ніж відповідний LPDDR, в рази. І є намір зменшити ще в 2-3 рази, перш за все для збільшення кількості чіпів HBM в прискорювачах AI.
на LikedIn спеціаліст Samsung з виробництва DRAM викладав дані про обєм памяті який вміщається на 1ну 300 мм пластину, в ТБайтах
Так HBM3 виходить в 3+ раз меньше ніж DDR5. Тому і ціна пластини в 3+ раз дорожча за той же обєм. Це все через широку шину - 1кбіт. HBM4 буде ще дорожча - шина 2кбіт
Інші перешкоди:
0. HBM память це 1-2 тісячі біт, 3-5 тисячі контактів, всі розміщені на площі 3 мм від краю кристалу, і для приєднання до проца вимагає кремнієвий інтерпозер, по суті чіп-посередник з доріжками на техпроцесі 22нм, і відповідний контролер і контакти мають бути в процесорі. Сама процедура приєднання точна і дорога без можливості ремонту.
1. HBM память в жахливому дефіциті - вона життєво важлива для AI, а зараз черга на прискорювачі на 3 роки вперед і 10+ міліонів штук (тільки Маск вже замовив пару міліонів), тож чіпів максимального обєму тре десятки міліонів, а кожен чіп це 12-16 кристалів по 2 Гбайт зєднані в один пакет десятками тисяч TSV зєднань наскрізь
2. По суті память дорога не тільки через обєм чіпа, а в основному через кількість кристалів в упаковці чіпа. Для планок ddr5 DRAM на 256 Гбайт чіпи на 16 Гбайт з 8 кристалів по 2 Гбайт в 5-10 раз дорожчий ніж чіп 4 кристали по 1,5 Гбайт для планок 48 Гбайт чи 8 кристалів по 1 Гбайт для планок 64 Гбайт
3. память максимально дешева лише при дуууже великих партіях закупки. Наприклад Інтел для своїх LunarLake, які продаються відразу з розпаяною LPDDR, незмогла домовитись задешево. Що тоді казати про купівлю HBM - замовляти тре на 300+ міліонів і гроші наперед
взагалі ваша пропозиція має раціональність, зарашні інтегровані відеокарти дуже потужні і могли б теж скористатись з HBM. Але тре навпаки 512 біт, не більше, щоб ціну здешевити. Також якщо рахувати ціну за ГБайт/с то HBM контролер памяті і його інтерфейс займає знааачно меньше місця на кристалі процесора чи APU ніж відповідний LPDDR, в рази. І є намір зменшити ще в 2-3 рази, перш за все для збільшення кількості чіпів HBM в прискорювачах AI.
Востаннє редагувалось 17.04.2025 21:50 користувачем ronemun, всього редагувалось 1 раз.
-
Scoffer
Member
yurius_r
Багато це значить багато. HBM зараз лютий дефіцит - величезний попит з боку датацентів і плюс де-факто цей тип пам'яті великосерійно випускає одна контора - Hynix, у самса все не виходить випустити нормальну серію, браку багато, мікрон там теж осилив щось чисто символічно. В той же час ту лпддр кожен дурень робить, включно з китайцями. Різниця в вартостях скоріш за все йде на десятки раз.
Відправлено через 10 хвилин 58 секунд:
А щодо ПСП в ноутах, то аплє тупо завезла 8 каналів лпддр в топових чіпах і чудово себе почуває. Це амд вперлась рогами в свої два канали, навіть не знаю як вони додумались аж до 4х в AI Max.
Багато це значить багато. HBM зараз лютий дефіцит - величезний попит з боку датацентів і плюс де-факто цей тип пам'яті великосерійно випускає одна контора - Hynix, у самса все не виходить випустити нормальну серію, браку багато, мікрон там теж осилив щось чисто символічно. В той же час ту лпддр кожен дурень робить, включно з китайцями. Різниця в вартостях скоріш за все йде на десятки раз.
Відправлено через 10 хвилин 58 секунд:
А щодо ПСП в ноутах, то аплє тупо завезла 8 каналів лпддр в топових чіпах і чудово себе почуває. Це амд вперлась рогами в свої два канали, навіть не знаю як вони додумались аж до 4х в AI Max.
-
yurius_r
Member
ronemun
Дякую за екскурс. Але я нагадаю ще про Xeon Max - де треба в Intel все виходить. Так, ціна там немаленька, але партії скоріш за все були мізерні.
Scoffer
Тобто "багато" це про ціну і дефіцит. Що там по затримках?
Дякую за екскурс. Але я нагадаю ще про Xeon Max - де треба в Intel все виходить. Так, ціна там немаленька, але партії скоріш за все були мізерні.
Scoffer
Тобто "багато" це про ціну і дефіцит. Що там по затримках?
Востаннє редагувалось 17.04.2025 23:06 користувачем yurius_r, всього редагувалось 1 раз.
-
vmsolver
Member
Ок, но ответ тот же: в этом нет смысла. Никому не нужна HBM, всем нужна производительность и объем за вменяемые деньги. HBM вписалась в тот рынок, которому нужны её достоинства и не так важны её недостатки, высокая цена, в частности.yurius_r: ↑ 17.04.2025 21:05Я не про GPU, яж написав про lpddr
-
Scoffer
Member
yurius_r
По затримкам в залежності від залежностей, але в 2-4 рази. HBM вигадана для "ПСП понад усе". Вона і заберпечує рекордну ПСП. Все інше від посередньо до погано.
По затримкам в залежності від залежностей, але в 2-4 рази. HBM вигадана для "ПСП понад усе". Вона і заберпечує рекордну ПСП. Все інше від посередньо до погано.
-
yurius_r
Member
Scoffer
Щодо скільки жере і не енергоефективна
Щодо скільки жере і не енергоефективна
Ось погуглив трохи https://massedcompute.com/faq-answers/? ... plications?HBM vs DDR Memory: HBM has three advantages over traditional DDR memory: higher memory bandwidth, higher capacity in a compact form factor, and improved power efficiency.
HBMA3 is a high-speed memory designed for data-intensive applications, such as artificial intelligence, machine learning, and high-performance computing. It offers a bandwidth of up to 3.2 TB/s and a latency of around 1.2-1.5 ns. This low latency enables fast data transfer and processing, making it an ideal choice for real-time data processing applications.
Comparison with Other High-Bandwidth Memory Technologies
Let's compare the latency of HBM3 with other high-bandwidth memory technologies:
GDDR6X: GDDR6X is a high-speed memory technology used in graphics cards and data center applications. It offers a bandwidth of up 1.2 TB/s and a latency of around 2-3 ns.
DDR5: DDR5 is a high-speed memory technology used in servers and data center applications. It offers a bandwidth of up to 6400 MT/s and a latency of around 2-3 ns.
LPDDR5X: LPDDR5X is a low-power memory technology used in mobile devices and data center applications. It offers a bandwidth of up to 6400 MT/s and a latency of around 2-3 ns.
HBM2: HBM2 is a high-speed memory technology used in data center applications. It offers a bandwidth of up to 1.6 TB/s and a latency of around 1.5-2 ns.
-
Scoffer
Member
yurius_r
Ага, одна наносекунда. А ~380 не хочеш?)
А щодо жере то це дивлячись з чим порівнювати. Якщо з розігнаною в хламидло гддрх, то так, економно, а якщо з лпддр, бо ти ж з неї почав, то все з точністю до навпаки.
Ага, одна наносекунда. А ~380 не хочеш?)
- спойлер

А щодо жере то це дивлячись з чим порівнювати. Якщо з розігнаною в хламидло гддрх, то так, економно, а якщо з лпддр, бо ти ж з неї почав, то все з точністю до навпаки.
-
ronemun
Advanced Member
yurius_r
HBM вже використовували як оперативу в процесорах і відмовились, коротке пояснення тут
Xeon Max - відносно нові, серверні аналоги core 14го покоління, тільки без е-ядер, лише p, до 60 шт.
HBM реально непризначена для того щоб видавати і приймати дані для одного ядра, чи навіть кількох одночасно.
Наприклад вся кільцева шина всередині core 14900k має швидкість 3,5ГГц*32 байт/с=100 Гбайт/с в кожну сторону- зчитування/запис, одночасно в обидві - 200. Навіть Ryzen 9950 хватає всього 100 Гбайт/с оперативи, і то це сумарно - і запис і зчитування паралельно.
А один чіп HBM має 800 Гбайт/с, новітні - 1200, а HBM4 буде 2000. Тобто явний надлишок ПСП.
Така ПСП потрібна лише там де її дефіцит - у відеокарт (але GDDR6 в 3 рази дешевша, а всі хочіть дешеві відяхи), і прискорювачах AI/gpgpu.
А ці пристрої маї 10+ тисяч ядер по 32біт на частотах 2-3 ГГц, і там всі ходи даних наперед прораховані, це їх особливість, тож дані пишуться/зчитуються величезними пакетами- мегабайти, а не кілобайти як процах - меньше не має сенсу, тому що час підготовки даних буде 50нс, а передача даних - 5, в 10 раз меньше, і відповідно вся шина і память і ядра будуть працювати лише 10% часу, решту простоювати. А навіщо тоді така шина? Тому все розраховано так щоб час передачі був значно більше ніж час підготовки щоб максимально використати шину - для цього є спецбуфери (HBM працює на своїй частоті не синхронно з прискорювачем, тому дані тре тимчасово зберегти в буфер перед передачею далі) і т.п. які працюють тільки з певним обємом за раз, а отже з певною оптимальною затримкою.
У відеокарт і т.п. така швидкість памяті необхідна бо вони завжди працюють відразу ВСІ сотні простих ядер і спецблоків - в geforce 5090 тільки шейдери 100 Тфлоп/с (400 кбайт/нс), і в них дуже малі робочі кеші (їх там багато типів), ще є L1 відразу для груп ядер по 128/256/512шт. При цьому там рідко дані використовуються повторно, особливо частково - це сильно сповільняє обробку, лише при спецобрахунках, тому приходиться часто дані скидати в память і потім скачувати знову. Тут непомагають навіть загальні кеші останнього рівня по 16-128Мбайт які додають зараз.
В процах ядра рідко працюють всі разом, ядра мають великі L2 + зєднані з великим кешом L3, дані часто використовуються багато раз, тож їм память потрібна лише коли дані невмістились або тре нові дані. Ядер мало і дані їм потрібно теж мало, але тільки необхідні і вже. Навіть Ryzen 9900х на 12 ядер коли обробляє максимально паралельний тест лінпак з AVX512 на швидкості 1.75 Тфлоп/с хватає всього 90 Гбайт/с швидкості ddr5. Але якщо збільшити час доступу хоча б з 70 до 100 нс швидкість обробки впаде в 1,5 рази.
HBM вже використовували як оперативу в процесорах і відмовились, коротке пояснення тут
Xeon Max - відносно нові, серверні аналоги core 14го покоління, тільки без е-ядер, лише p, до 60 шт.
HBM реально непризначена для того щоб видавати і приймати дані для одного ядра, чи навіть кількох одночасно.
Наприклад вся кільцева шина всередині core 14900k має швидкість 3,5ГГц*32 байт/с=100 Гбайт/с в кожну сторону- зчитування/запис, одночасно в обидві - 200. Навіть Ryzen 9950 хватає всього 100 Гбайт/с оперативи, і то це сумарно - і запис і зчитування паралельно.
А один чіп HBM має 800 Гбайт/с, новітні - 1200, а HBM4 буде 2000. Тобто явний надлишок ПСП.
Така ПСП потрібна лише там де її дефіцит - у відеокарт (але GDDR6 в 3 рази дешевша, а всі хочіть дешеві відяхи), і прискорювачах AI/gpgpu.
А ці пристрої маї 10+ тисяч ядер по 32біт на частотах 2-3 ГГц, і там всі ходи даних наперед прораховані, це їх особливість, тож дані пишуться/зчитуються величезними пакетами- мегабайти, а не кілобайти як процах - меньше не має сенсу, тому що час підготовки даних буде 50нс, а передача даних - 5, в 10 раз меньше, і відповідно вся шина і память і ядра будуть працювати лише 10% часу, решту простоювати. А навіщо тоді така шина? Тому все розраховано так щоб час передачі був значно більше ніж час підготовки щоб максимально використати шину - для цього є спецбуфери (HBM працює на своїй частоті не синхронно з прискорювачем, тому дані тре тимчасово зберегти в буфер перед передачею далі) і т.п. які працюють тільки з певним обємом за раз, а отже з певною оптимальною затримкою.
У відеокарт і т.п. така швидкість памяті необхідна бо вони завжди працюють відразу ВСІ сотні простих ядер і спецблоків - в geforce 5090 тільки шейдери 100 Тфлоп/с (400 кбайт/нс), і в них дуже малі робочі кеші (їх там багато типів), ще є L1 відразу для груп ядер по 128/256/512шт. При цьому там рідко дані використовуються повторно, особливо частково - це сильно сповільняє обробку, лише при спецобрахунках, тому приходиться часто дані скидати в память і потім скачувати знову. Тут непомагають навіть загальні кеші останнього рівня по 16-128Мбайт які додають зараз.
В процах ядра рідко працюють всі разом, ядра мають великі L2 + зєднані з великим кешом L3, дані часто використовуються багато раз, тож їм память потрібна лише коли дані невмістились або тре нові дані. Ядер мало і дані їм потрібно теж мало, але тільки необхідні і вже. Навіть Ryzen 9900х на 12 ядер коли обробляє максимально паралельний тест лінпак з AVX512 на швидкості 1.75 Тфлоп/с хватає всього 90 Гбайт/с швидкості ddr5. Але якщо збільшити час доступу хоча б з 70 до 100 нс швидкість обробки впаде в 1,5 рази.
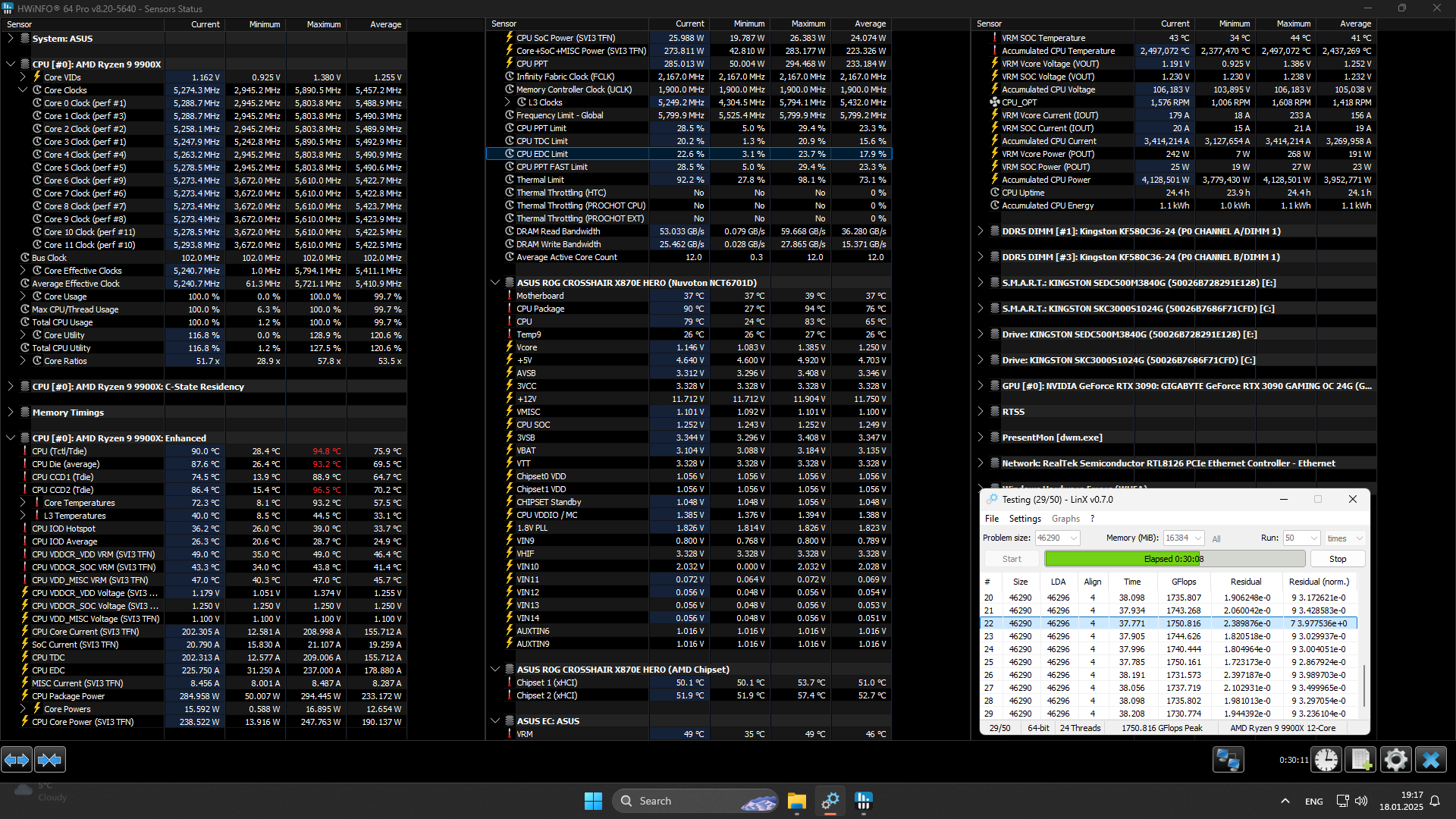{kind=link}
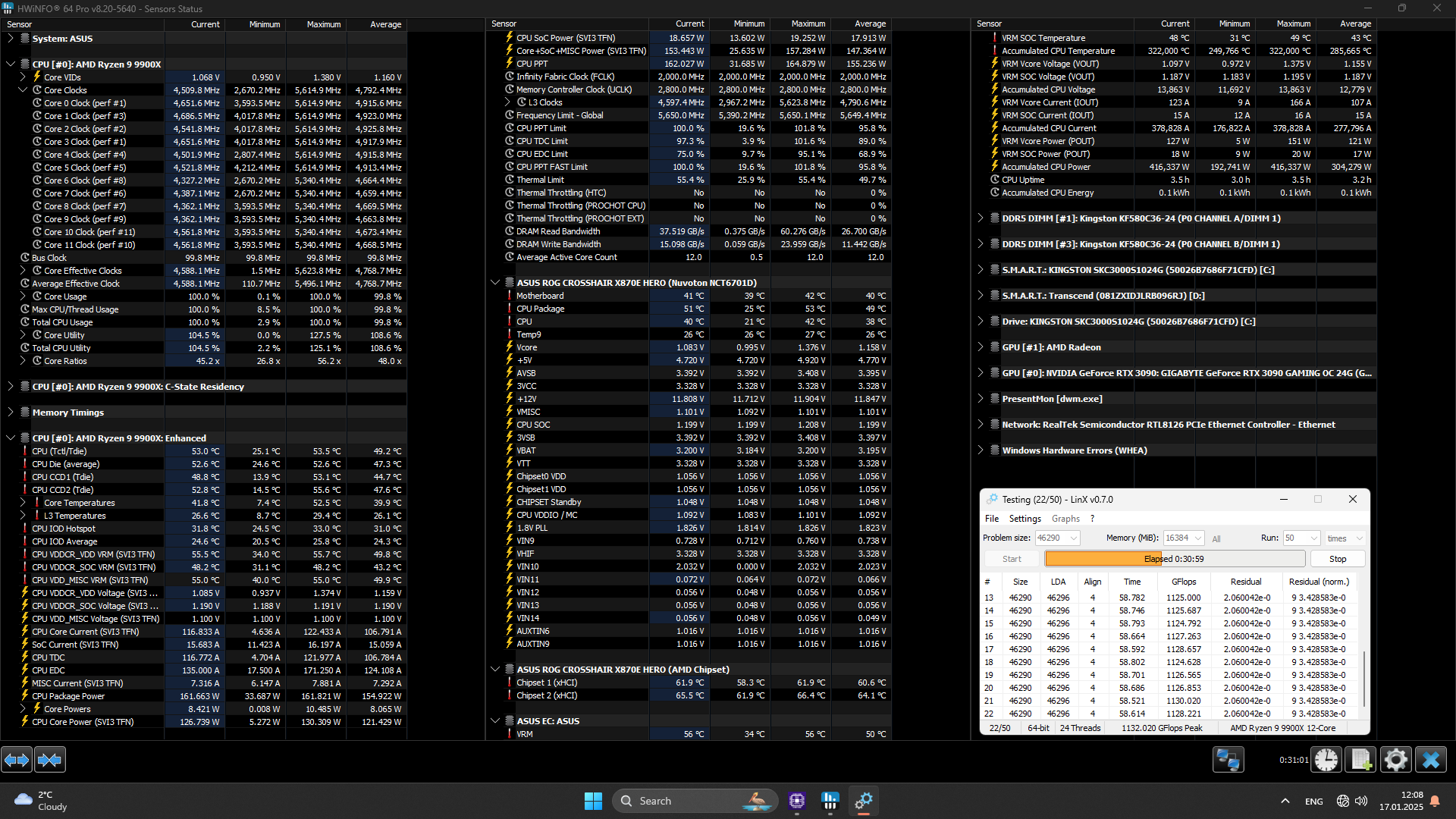{kind=link}
-
Scoffer
Member
ronemun
Так, зіони макс вийшли смішними пристроями. Зі сторони CPU-завдань вони заткнулись в затримки, а зі сторони AI-завдань в низьку пропускну спроможність внутрішніх шин. Навіть швидкість кешу L1 не вивозить завантажити AMX-прискорювач на 100%
Так, зіони макс вийшли смішними пристроями. Зі сторони CPU-завдань вони заткнулись в затримки, а зі сторони AI-завдань в низьку пропускну спроможність внутрішніх шин. Навіть швидкість кешу L1 не вивозить завантажити AMX-прискорювач на 100%
-
yurius_r
Member
Scoffer
Ти мені зараз показав якийсь графік роботи чогось на CUDA по доступу у shared, що як я розумію зовнішня пам'ять. До чого воно тут на прикладі присклрювача? Я знайшов академічне порівняння пам'яті без омобливостей реалізації. По споживанню я так розумію це лише твої здогадки без деталей?
Відправлено через 15 хвилин 36 секунд:
ronemun
Дякую за статтю. 130ns latency непогано. В кінці там досить простий висновок - як ядер стане вдвічі більше, воно буде ефективне, хоча і так дає bandwidth в 2.5-3.5 рази ширший за ddr5.
Ти мені зараз показав якийсь графік роботи чогось на CUDA по доступу у shared, що як я розумію зовнішня пам'ять. До чого воно тут на прикладі присклрювача? Я знайшов академічне порівняння пам'яті без омобливостей реалізації. По споживанню я так розумію це лише твої здогадки без деталей?
Відправлено через 15 хвилин 36 секунд:
ronemun
Дякую за статтю. 130ns latency непогано. В кінці там досить простий висновок - як ядер стане вдвічі більше, воно буде ефективне, хоча і так дає bandwidth в 2.5-3.5 рази ширший за ddr5.
-
Scoffer
Member
yurius_r
Ти знайшов якусь бредятину. Одна наносекунда затримки це порядок чисел L1 кешу, зовнішня пам'ять будь-якого типу як мінімум в десятки раз повільніше. Реальні затримки HBM складають від 150 (xeon max) до 400+ (відеокарти і інші прискорювачі) нс в залежності від того наскільки вона розкочегарена по частоті і жору. В той же час lpddr5 це щось порядку сотні, і 50-60нс для десктопної ддр середнього пошибу.
Щодо жору, то мінімальна базова напруга LPDDR5x це 1.01В зі зменшенням в простої, а самої козирної HBM3E - 1.1 без можливості динамічної зміни. Висновки очевидні.
Зав'язуй зі своїми чатами жпт. Теж мені знайшов цінне джерело інфи
Відправлено через 22 хвилини 20 секунд:
Ти знайшов якусь бредятину. Одна наносекунда затримки це порядок чисел L1 кешу, зовнішня пам'ять будь-якого типу як мінімум в десятки раз повільніше. Реальні затримки HBM складають від 150 (xeon max) до 400+ (відеокарти і інші прискорювачі) нс в залежності від того наскільки вона розкочегарена по частоті і жору. В той же час lpddr5 це щось порядку сотні, і 50-60нс для десктопної ддр середнього пошибу.
Щодо жору, то мінімальна базова напруга LPDDR5x це 1.01В зі зменшенням в простої, а самої козирної HBM3E - 1.1 без можливості динамічної зміни. Висновки очевидні.
Зав'язуй зі своїми чатами жпт. Теж мені знайшов цінне джерело інфи
Відправлено через 22 хвилини 20 секунд:
І ні, це не недолік для цього типу пам'яті. Так і заплановано. Сервера що недоутилізують обчислювальну потужність - погано заюзані сервера. Це не ноутбук, режими енергозбереження там нафіг не потрібні.Scoffer: ↑ 19.04.2025 01:18без можливості динамічної зміни
-
yurius_r
Member
Scoffer
Коротше про своє перше питання я зрозумів що якийсь сенс має лише ціна, всі інші речі надумані та висмоктані з пальця
Тобто різниця складає 3 рази? Серйозно? Тобто в прискорювачах для ШІ вона недорозкачегарена чи як? В Max там наміріли 130, а не 150. Різниця із 100+ lpddr несуттєва. До того ж я тобі нагадаю про такий досить нішевий продукт i7 8809g, на якому вироблялися ноути.Реальні затримки HBM складають від 150 (xeon max) до 400+ (відеокарти і інші прискорювачі) нс в залежності від того наскільки вона розкочегарена по частоті і жору
Коротше про своє перше питання я зрозумів що якийсь сенс має лише ціна, всі інші речі надумані та висмоктані з пальця
-
Scoffer
Member
yurius_r
Дивись тести. Так, в три раза. В чому проблема? GDDR5 для прикладу почалась з 3.6Гб/с з піна на 60нм техпроцесі, і закінчилась на 8Гб/с на 20нм, мала дуже різні затримки і жерла по-різному в рази, залишаючись все ще GDDR5.
Тим часом в зіон макс наміряли що з ростом пропускної спроможності затримки лише ростуть
До чого тут твій i7-8809G взагалі не зрозуміло, це не APU, в ньому окрема дискретна відеокарта з окремою виділеною для нею пам'ятю, до котрої проц напряму доступу не має.
Дивись тести. Так, в три раза. В чому проблема? GDDR5 для прикладу почалась з 3.6Гб/с з піна на 60нм техпроцесі, і закінчилась на 8Гб/с на 20нм, мала дуже різні затримки і жерла по-різному в рази, залишаючись все ще GDDR5.
Тим часом в зіон макс наміряли що з ростом пропускної спроможності затримки лише ростуть
- спойлер
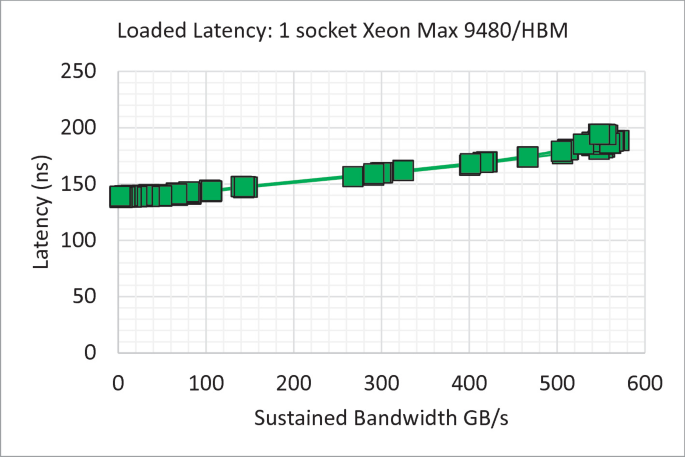
До чого тут твій i7-8809G взагалі не зрозуміло, це не APU, в ньому окрема дискретна відеокарта з окремою виділеною для нею пам'ятю, до котрої проц напряму доступу не має.