
Безстрокова промоакція зниження цін нового покоління. давно пора
Останні статті і огляди
Новини
AMD оголосила дату релізу процесорів Ryzen 9000X3D
-
aaleksandrenko
Member

- Звідки: Житомир
Пропоную обговорити AMD оголосила дату релізу процесорів Ryzen 9000X3D
Безстрокова промоакція зниження цін нового покоління. давно пора")
Безстрокова промоакція зниження цін нового покоління. давно пора
-
VRoman
Member
- Звідки: Albuquerque, NM, USA
Уже бьют ценами не успевшее выйти поколение Интел? 
-
WorthyWizard
Member
Та интел голову поднять не успевает, им даже похайпить новым поколением не дают. К тому же, уже ставшие мемом -5% arrow lake ситуацию не улучшают
-
Nortrom
Member

К тому же, уже ставшие мемом -5% arrow lake ситуацию не улучшают
https://x.com/9550pro/status/1848243780186698099
-
Nekros
Junior
Приблизно стільки же у многопотоці набирає і 9950ХNortrom: ↑ 21.10.2024 17:41К тому же, уже ставшие мемом -5% arrow lake ситуацию не улучшают
https://x.com/9550pro/status/1848243780186698099
-
Nikolay Yeryomenko
Member
Тут кстати есть новость по этому поводу: https://wccftech.com/intel-core-ultra-9 ... treme-mode
P.S. Всё таки хоть какая-то конкуренция есть. А в играх, да с X3D ему конечно не тягаться.
P.S. Всё таки хоть какая-то конкуренция есть. А в играх, да с X3D ему конечно не тягаться.
-
daesz
Member

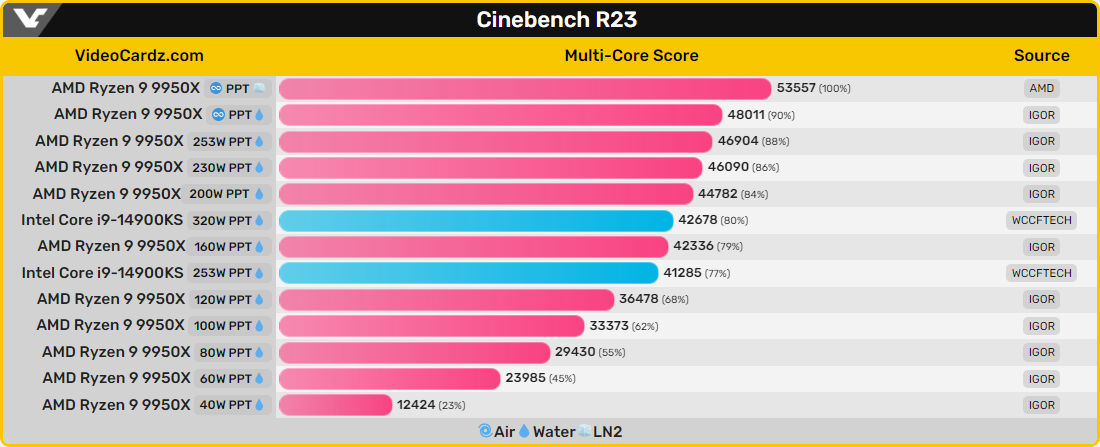
Приблизно (+5к)
Відправлено через 4 хвилини 15 секунд:
Конкуренція хіба в обігріванні квартири зимоюNikolay Yeryomenko: ↑ 21.10.2024 17:47 Тут кстати есть новость по этому поводу: https://wccftech.com/intel-core-ultra-9 ... treme-mode
P.S. Всё таки хоть какая-то конкуренция есть. А в играх, да с X3D ему конечно не тягаться.
-
ronemun
Advanced Member
дивує Інтел - в свій топ вони напхали кешу L3 12*3=36МБ і 8*3+4*4=40 МБ L2, всього 76
Невже важко добавити ще 36 МБ L3, довести до 72, в сумі з L2 буде 112, щоб перебити 104 у АМД?
з розрахунку 3МБ кешу на 1мм2 (на техроцесі 3нм TSMC) це додатково всього 12-14 мм2,
Очевидно ж що 36 МБ L3 явно замало для 24 ядер, та ще й з заниженою частотою кільцевої шини
А ще гірше для проців з меншою кількістю ядер, адже в Інтел кеш L3 йде пропорційно станціям, тож у 6р+2*4е буде всього 24МБ L3 - просто смішно зараз для 14 ядер.
Ще розумію раніше, на своєму дорогому техпроцесі, планували ще до ери 3д кешу, а зараз все нове і на TSMC 3нм - чого скупитись?
В Apple вже більше кешу в смартфонах і в ультрабуках
АМД ж ніколи не жаліла, і навіть у 6 ядер кеш 32МБ, а зараз 96, і профіт явний, а ціна - копійки
А головне, кеш - це просто комірки SRAM, по суті - сміття, тупо 1 біт інформації, і все. Множ скільки хочеш, а плати лише за площу
Меньше НЕ МОЖЕ БУТИ. 4 транзистори на 1 біт, і ще 2 транзистори для управління.
Але на TSMC 3нм на 1 мм2 влізається мінімум 24 МБіт SRAM, це видно по фото кристалів Zen5 і Intel Lunar Lake
Невже важко добавити ще 36 МБ L3, довести до 72, в сумі з L2 буде 112, щоб перебити 104 у АМД?
з розрахунку 3МБ кешу на 1мм2 (на техроцесі 3нм TSMC) це додатково всього 12-14 мм2,
Очевидно ж що 36 МБ L3 явно замало для 24 ядер, та ще й з заниженою частотою кільцевої шини
А ще гірше для проців з меншою кількістю ядер, адже в Інтел кеш L3 йде пропорційно станціям, тож у 6р+2*4е буде всього 24МБ L3 - просто смішно зараз для 14 ядер.
Ще розумію раніше, на своєму дорогому техпроцесі, планували ще до ери 3д кешу, а зараз все нове і на TSMC 3нм - чого скупитись?
В Apple вже більше кешу в смартфонах і в ультрабуках
АМД ж ніколи не жаліла, і навіть у 6 ядер кеш 32МБ, а зараз 96, і профіт явний, а ціна - копійки
А головне, кеш - це просто комірки SRAM, по суті - сміття, тупо 1 біт інформації, і все. Множ скільки хочеш, а плати лише за площу
Меньше НЕ МОЖЕ БУТИ. 4 транзистори на 1 біт, і ще 2 транзистори для управління.
Але на TSMC 3нм на 1 мм2 влізається мінімум 24 МБіт SRAM, це видно по фото кристалів Zen5 і Intel Lunar Lake
Востаннє редагувалось 21.10.2024 20:15 користувачем ronemun, всього редагувалось 1 раз.
-
Nekros
Junior
daesz: ↑ 21.10.2024 18:01
Приблизно (+5к)
Відправлено через 4 хвилини 15 секунд:Конкуренція хіба в обігріванні квартири зимоюNikolay Yeryomenko: ↑ 21.10.2024 17:47 Тут кстати есть новость по этому поводу: https://wccftech.com/intel-core-ultra-9 ... treme-mode
P.S. Всё таки хоть какая-то конкуренция есть. А в играх, да с X3D ему конечно не тягаться.
-
daesz
Member
+7.5% відносно 14900к (200 папугаїв різниці), а 14900к повільніший за у285к зі слів штеудаNekros: ↑ 21.10.2024 20:13daesz: ↑ 21.10.2024 18:01
Приблизно (+5к)
Відправлено через 4 хвилини 15 секунд:
Конкуренція хіба в обігріванні квартири зимою
-
Volodya811
Member
У Інтела кеш L2 - 3 МБ на ядро, проти 1 МБ у АМД. Кеш L2 дуже дорогий, бо займає велику площу. Збільшення кешу L2 у Раптор Лайк вивело цей процесор на зовсім інший рівень в іграх. Кеш L3 для Інтела менш важливий, оскільки великий L2 і нормальний контролер пам'яті. Такого приросту, як у АМД не буде.ronemun: ↑ 21.10.2024 20:06 дивує Інтел - в свій топ вони напхали кешу L3 12*3=36МБ і 8*3+4*4=40 МБ L2, всього 76
Невже важко добавити ще 36 МБ L3, довести до 72, в сумі з L2 буде 112, щоб перебити 104 у АМД?
з розрахунку 3МБ кешу на 1мм2 (на техроцесі 3нм TSMC) це додатково всього 12-14 мм2,
Очевидно ж що 36 МБ L3 явно замало для 24 ядер, та ще й з заниженою частотою кільцевої шини
А ще гірше для проців з меншою кількістю ядер, адже в Інтел кеш L3 йде пропорційно станціям, тож у 6р+2*4е буде всього 24МБ L3 - просто смішно зараз для 14 ядер.
Ще розумію раніше, на своєму дорогому техпроцесі, планували ще до ери 3д кешу, а зараз все нове і на TSMC 3нм - чого скупитись?
В Apple вже більше кешу в смартфонах і в ультрабуках
АМД ж ніколи не жаліла, і навіть у 6 ядер кеш 32МБ, а зараз 96, і профіт явний, а ціна - копійки
А головне, кеш - це просто комірки SRAM, по суті - сміття, тупо 1 біт інформації, і все. Множ скільки хочеш, а плати лише за площу
Меньше НЕ МОЖЕ БУТИ. 4 транзистори на 1 біт, і ще 2 транзистори для управління.
Але на TSMC 3нм на 1 мм2 влізається мінімум 24 МБіт SRAM, це видно по фото кристалів Zen5 і Intel Lunar Lake
Крім того, чим більший кеш - тим більша латентність цього кешу. Ми пам'ятаємо, що Рокет Лайк маючи на 17-19% вищий ІРС і в два рази більший кеш L2, ніж Скайлайк - в іграх того часу переваги не мав.
Думаю, що тут проблема в чомусь іншому. Можливо, через чіплетну аріхітектуру.
-
waryag
Member

- Звідки: Суми
Жаліла, ще й як.ronemun: ↑ 21.10.2024 20:06АМД ж ніколи не жаліла, і навіть у 6 ядер кеш 32МБ, а зараз 96, і профіт явний, а ціна - копійки
А головне, кеш - це просто комірки SRAM, по суті - сміття, тупо 1 біт інформації, і все. Множ скільки хочеш, а плати лише за площу
Меньше НЕ МОЖЕ БУТИ. 4 транзистори на 1 біт, і ще 2 транзистори для управління.
Але на TSMC 3нм на 1 мм2 влізається мінімум 24 МБіт SRAM, це видно по фото кристалів Zen5 і Intel Lunar Lake
Від 3800х до 9700х залишили обсяг Л3 без змін і збільшили Л2 всього до 1МБ, при тому, що транзисторний бюджет виріс вдвічі. Так, є х3д, але він стосується лише невеликої частини процесорів.
У моночипах два перших покоління мали всього 8МБ Л3, і тільки з зен3 отримали мінімально пристойні 16.
-
ronemun
Advanced Member
waryag
Volodya811
Я теж погоджуюсь що 32Мбайт в Райзен 9700х замало, але ж 32 Мбайт на 8 ядер явно краще ніж 36мбайт на 24 ядра у 285к чи 24 Мбайт на 14 ядер у 245k. Тим більше в АМД 6-ядерник теж має 32Мбайт.
Тре розуміти, що в АМД швидкість кільцевої шини у 2-3 рази більша, в тестах дає всі 32 байт/такт (в кожну сторону) проти 16 в Інтел, при цьому в АМД чатота кільця рівна частоті ядер, тоді як у Інтел вона завжди мала, нижча за частоту е-ядер, що ще більше збільшує затримку доступу до інших банок кешу коли йде інтенсивна обробка і попереднє кешування зчитування з оперативи. Саме це заставило Інтел збільшити L2, щоб меньше звертатись в L3, але L2 не поможе якщо память тормозить і дані тре кешувати з оперативи на БАГАТО Мбайт наперед, адже L2 невеликий бо він тільки свій. Великий L2 потрібен лише при дуже інтенсивній обробці даних в тому ж ядрі, бо L2 має малу затримку, і щоб меньше залежати при малому і повільному L3, який може бути зайнятий чужими ядрами. Але в АМД хватає 1МБайт L2 на ядро навіть на тій же частоті і при такому ж потужному ядрі, як у Інтел, але а АМД ще й при цьому включений SMT, це ще +25-100% навантаження, і ще й при AVX512 на повній швидкості.
Тож елементарне збільшення банок L3 в Інтел знаачно зменшило б біганину по сусіднім банкам, розгрузило б кільцеву шину для інших задач, а 8-12 таких банок це ще плюс 24-36 мбайт L3 забезпечило б ефективне кешування тормознутої ddr5 в іграх, архіваторах і інших задачах з частим звертанням в оперативу
Volodya811
SRAM в кеші L2 на одиницю обєму у процах АМД займає майже ту ж площу що й L3. Звичайно, трохи більше, адже він розбитий на менші порції, 32кбайт проти 64, але в загальному площа більша лише на 15%. А в Інтел взагалі площа таж сама, бо кеш L2 великий, часто більше ніж L3, і порції розбиття однакові. В e-ядер в core 13-14 кеш L2 ще плотніший ніж L3, як не дивно, 0.45мм2/1Мбайт проти 0,55
Цитата:Збільшення кешу L2 у Раптор Лайк вивело цей процесор на зовсім інший рівень в іграх
Ні, сама Інтел приписувала ріст IPC лише на 2%, це аналогічно підняти частоту з 5,0 до 5,1ГГц
Інтел збільшила L2 до 2 мбайт тому що в неї : а) повільне і довге кільце - не 8 як у АМД, а всі 12+2 станції, тобто довший шлях до інших банок, та ще й ширина шини кільця меньша, і частота теж. Тому L3 в Інтел явно повільніший, і це прийшлось компенсувати більшим L2 щоб зменшити звертання в L3 при інтенсивній обробці. б) тому що в Інтел розробляло 1 ядро, а головне все в серверах, а там шина кільця ще повільніша, вона як сітка, а банки L3 всього по 1,87Мбайт, при тому ж потужні ядра з AVX512+блоки FMA3+AMX(ШІ), тож L2 все це мав швидко годувати. А потім ці ядра перейшли в десктопи без змін щоб не малювати нові маски, бо дорого, просто відключили AVX512iFMA, а AMX взагалі забрали. В нових LionCove все нове, навіть ядра для десктопа і сервера різні, тож могли вліпити L3 побільше
Volodya811
Я теж погоджуюсь що 32Мбайт в Райзен 9700х замало, але ж 32 Мбайт на 8 ядер явно краще ніж 36мбайт на 24 ядра у 285к чи 24 Мбайт на 14 ядер у 245k. Тим більше в АМД 6-ядерник теж має 32Мбайт.
Тре розуміти, що в АМД швидкість кільцевої шини у 2-3 рази більша, в тестах дає всі 32 байт/такт (в кожну сторону) проти 16 в Інтел, при цьому в АМД чатота кільця рівна частоті ядер, тоді як у Інтел вона завжди мала, нижча за частоту е-ядер, що ще більше збільшує затримку доступу до інших банок кешу коли йде інтенсивна обробка і попереднє кешування зчитування з оперативи. Саме це заставило Інтел збільшити L2, щоб меньше звертатись в L3, але L2 не поможе якщо память тормозить і дані тре кешувати з оперативи на БАГАТО Мбайт наперед, адже L2 невеликий бо він тільки свій. Великий L2 потрібен лише при дуже інтенсивній обробці даних в тому ж ядрі, бо L2 має малу затримку, і щоб меньше залежати при малому і повільному L3, який може бути зайнятий чужими ядрами. Але в АМД хватає 1МБайт L2 на ядро навіть на тій же частоті і при такому ж потужному ядрі, як у Інтел, але а АМД ще й при цьому включений SMT, це ще +25-100% навантаження, і ще й при AVX512 на повній швидкості.
Тож елементарне збільшення банок L3 в Інтел знаачно зменшило б біганину по сусіднім банкам, розгрузило б кільцеву шину для інших задач, а 8-12 таких банок це ще плюс 24-36 мбайт L3 забезпечило б ефективне кешування тормознутої ddr5 в іграх, архіваторах і інших задачах з частим звертанням в оперативу
Volodya811
SRAM в кеші L2 на одиницю обєму у процах АМД займає майже ту ж площу що й L3. Звичайно, трохи більше, адже він розбитий на менші порції, 32кбайт проти 64, але в загальному площа більша лише на 15%. А в Інтел взагалі площа таж сама, бо кеш L2 великий, часто більше ніж L3, і порції розбиття однакові. В e-ядер в core 13-14 кеш L2 ще плотніший ніж L3, як не дивно, 0.45мм2/1Мбайт проти 0,55
Цитата:Збільшення кешу L2 у Раптор Лайк вивело цей процесор на зовсім інший рівень в іграх
Ні, сама Інтел приписувала ріст IPC лише на 2%, це аналогічно підняти частоту з 5,0 до 5,1ГГц
Інтел збільшила L2 до 2 мбайт тому що в неї : а) повільне і довге кільце - не 8 як у АМД, а всі 12+2 станції, тобто довший шлях до інших банок, та ще й ширина шини кільця меньша, і частота теж. Тому L3 в Інтел явно повільніший, і це прийшлось компенсувати більшим L2 щоб зменшити звертання в L3 при інтенсивній обробці. б) тому що в Інтел розробляло 1 ядро, а головне все в серверах, а там шина кільця ще повільніша, вона як сітка, а банки L3 всього по 1,87Мбайт, при тому ж потужні ядра з AVX512+блоки FMA3+AMX(ШІ), тож L2 все це мав швидко годувати. А потім ці ядра перейшли в десктопи без змін щоб не малювати нові маски, бо дорого, просто відключили AVX512iFMA, а AMX взагалі забрали. В нових LionCove все нове, навіть ядра для десктопа і сервера різні, тож могли вліпити L3 побільше
-
l-m
Member
Десь помилка, я міряв, та виходить що L3 приблизно на 73% щільніше.ronemun: ↑ 22.10.2024 01:01 SRAM в кеші L2 на одиницю обєму у процах АМД займає майже ту ж площу що й L3. Звичайно, трохи більше, адже він розбитий на менші порції, 32кбайт проти 64, але в загальному площа більша лише на 15%.
Можливо ти поміряв тільки самі комірки, але так робити не вірно.