
Підкажіть що за "ШІ-застосунки", що для них аж частину масового процессора віддали, замість додати ядер, чи посилити вбудоване відео? Хоч один?Це, за заявами AMD, забезпечить в три рази більшу продуктивність у ШІ-застосунках щодо актуальних Ryzen 8040 (Hawk Point),
Останні статті і огляди
Новини
Мобільні процесори AMD Strix Point отримають вбудовану графіку RDNA 3+
-
VovaII
Member

Пропоную обговорити Мобільні процесори AMD Strix Point отримають вбудовану графіку RDNA 3+
-
Dilfin
Member
Це треба в маленького цукерберга питати з його метавсесвітом, де там у фейсбук використовується штучний інтелект, на мою думку там взагалі інтелекту немає.VovaII: ↑ 22.03.2024 11:51 Пропоную обговорити Мобільні процесори AMD Strix Point отримають вбудовану графіку RDNA 3+
Підкажіть що за "ШІ-застосунки", що для них аж частину масового процессора віддали, замість додати ядер, чи посилити вбудоване відео? Хоч один?Це, за заявами AMD, забезпечить в три рази більшу продуктивність у ШІ-застосунках щодо актуальних Ryzen 8040 (Hawk Point),
-
vmsolver
Member
Заметим разницу в подходах в разработке архитектур, АМД делает что-то, а потом выпускает промежуточные варианты перед выпуском следующей архитектуры, такое впечатление что сразу они сделать не успевают и делают хоть что-то, а потом допиливают. У Nvidia подход другой, они сразу делают архитектуру и вместо доделок и промежуточных вариантов сразу делают следующую. Последняя деталь в картине: цикл производства у АМД это один год, у Nvidia два года. Nvidia не пытается делать релиз каждый год, даже они со своими бюджетами понимают, что за год сделать что-то новое очень трудно или невозможно. В итоге, похоже, АМД движет маркетинг, больше новых продуктов - больше продаж.
-
Scoffer
Member

vmsolver
В АМД правлять клінічні ідіоти. Зараз на одних лише APU випускається одночасно zen2, zen3 i zen4 з вбудованими графіками GCN, RDNA2, RDNA3 i буде ще й RDNA3+. При чому періодами в самих маразматичних поєднаннях, типу Ryzen 7 7730U = zen3+GCN+7нм і це даунгрейд з райзенів 6ххх, котрі були Zen 3+ + RDNA2 + 6нм техпроцес
А потім щось з дровами не ходиться. Дійсно, з чого б?
В АМД правлять клінічні ідіоти. Зараз на одних лише APU випускається одночасно zen2, zen3 i zen4 з вбудованими графіками GCN, RDNA2, RDNA3 i буде ще й RDNA3+. При чому періодами в самих маразматичних поєднаннях, типу Ryzen 7 7730U = zen3+GCN+7нм і це даунгрейд з райзенів 6ххх, котрі були Zen 3+ + RDNA2 + 6нм техпроцес
А потім щось з дровами не ходиться. Дійсно, з чого б?
-
SergiusTheBest
Member
- Звідки: Київ
По тестам воно трохи менше енергії жере, ніж робити те саме на відеоядрах. Застосунки: наприклад розмиття фону при відеодзвінках.VovaII: ↑ 22.03.2024 11:51 Підкажіть що за "ШІ-застосунки", що для них аж частину масового процессора віддали, замість додати ядер, чи посилити вбудоване відео? Хоч один?
-
Scoffer
Member
Та не трохи. За оцінками гугла, їхні TPU жруть раз в 5 менше за повноціну відяху на одному і тому ж самому матричному завданні. Тому їх реально є сенс винести в окремий співпроцесор/прискорювач. Також є сенс винести з відяхи числодробильню в окремий DSP співпроцесор/прискорювач замість GPGPU по тим же самим причинам. Все це вже реалізовано в еплопроцах і снапдрагоні, наприклад.
Відправлено через 8 хвилин 37 секунд:
А ще у АМД випускається ryzen z1, котрий формально zen4+rdna3, от тільки це rdna3- бо покоцана на матричні прискоренняScoffer: ↑ 22.03.2024 12:46APU випускається одночасно zen2, zen3 i zen4 з вбудованими графіками GCN, RDNA2, RDNA3 i буде ще й RDNA3+
-
SergiusTheBest
Member
- Звідки: Київ
Я дивився по реальним тестам, то там різниця була не сильно велика (мова йде саме про NPU вбудований в мобільний процесор) - здається десь 30%.Scoffer: ↑ 22.03.2024 13:01 Та не трохи. За оцінками гугла, їхні TPU жруть раз в 5 менше за повноціну відяху на одному і тому ж самому матричному завданні.
-
Afit
Member

- Звідки: Запорожье
А варіанти Super, чи Ti - це не допилені версіїvmsolver: ↑ 22.03.2024 12:34 Заметим разницу в подходах в разработке архитектур, АМД делает что-то, а потом выпускает промежуточные варианты перед выпуском следующей архитектуры, такое впечатление что сразу они сделать не успевают и делают хоть что-то, а потом допиливают. У Nvidia подход другой, они сразу делают архитектуру и вместо доделок и промежуточных вариантов сразу делают следующую. Последняя деталь в картине: цикл производства у АМД это один год, у Nvidia два года. Nvidia не пытается делать релиз каждый год, даже они со своими бюджетами понимают, что за год сделать что-то новое очень трудно или невозможно. В итоге, похоже, АМД движет маркетинг, больше новых продуктов - больше продаж.
-
Scoffer
Member
SergiusTheBest
У тебе не чистий тест, ти ж не вимикав всі інші частини APU щоб заміряти NPU vs GPU.
У тебе не чистий тест, ти ж не вимикав всі інші частини APU щоб заміряти NPU vs GPU.
-
SergiusTheBest
Member
- Звідки: Київ
Міряли загальне споживання в залежності від режиму роботи CPU/GPU/NPU. По різниці можна зробити висновки, що на скільки добре працює: NPU самий енергоефективний і швидше за CPU, GPU ще швидше, але і енергії їсть більше. Поки не зрозуміло, на скільки приживуться NPU. Їх може спіткати доля прискорювачів PhysXScoffer: ↑ 22.03.2024 14:18 У тебе не чистий тест, ти ж не вимикав всі інші частини APU щоб заміряти NPU vs GPU.
-
divinity
Member
З дровами все норм. Але багато топ проців з топ (відносно) графікою, але мало середніх проців з топ встройкою... тому все одно ставлять топ проци з дискреткою в ноути, а бюджетний геймінг такий в ПК, що простіше і дешевше дискретку теж купити. Тому позиціонування багатьох продуктів дивне.Scoffer: ↑ 22.03.2024 12:46 vmsolver
В АМД правлять клінічні ідіоти. Зараз на одних лише APU випускається одночасно zen2, zen3 i zen4 з вбудованими графіками GCN, RDNA2, RDNA3 i буде ще й RDNA3+. При чому періодами в самих маразматичних поєднаннях, типу Ryzen 7 7730U = zen3+GCN+7нм і це даунгрейд з райзенів 6ххх, котрі були Zen 3+ + RDNA2 + 6нм техпроцес
А потім щось з дровами не ходиться. Дійсно, з чого б?
-
Koluchiy
Member
- Звідки: Kyiv
Мене те ж весь час дивує - нахіба топовим процам топова вбудована графіка, все одно ж дискретку в ноут поставлять. А ось якраз на 4-х та 6-ти ядерниках сенсу у топовій вбудованій графіці більшеdivinity: ↑ 22.03.2024 15:02 З дровами все норм. Але багато топ проців з топ (відносно) графікою, але мало середніх проців з топ встройкою... тому все одно ставлять топ проци з дискреткою в ноути, а бюджетний геймінг такий в ПК, що простіше і дешевше дискретку теж купити. Тому позиціонування багатьох продуктів дивне.
-
vmsolver
Member
Они основаны на тех же чипах и архитектура у них такая же как и у остальной линейки.
-
Scoffer
Member
divinity
З кількістю ядер там все як треба. В грамотно зробленій грі буде завантажуватись не одне ядро, а 8 на 1/8 кожне, і це сильно економічніше енергетично.
А от тримати від 3х до 5, дивлячись як рахувати, графічних архітектур і три з половиною процесорні архітектури в одному поколінні APU - абсолютна наркоманія. Так ніяких драйверописців не вистачить.
З кількістю ядер там все як треба. В грамотно зробленій грі буде завантажуватись не одне ядро, а 8 на 1/8 кожне, і це сильно економічніше енергетично.
А от тримати від 3х до 5, дивлячись як рахувати, графічних архітектур і три з половиною процесорні архітектури в одному поколінні APU - абсолютна наркоманія. Так ніяких драйверописців не вистачить.
-
ronemun
Advanced Member
1. NPU, як і будь-який прискорювач, в т.ч. графічний, майнінг, і т.п., вимагає попередньої обробки на проці, і повністю може відкритись на великих моделях, з довгим періодом розрахунку на прискорювачі, вірніше, коли час роботи проца відносно всього обрахунку мінімальний. А коли дають маленьку модель, для якої підготовка обробки на проці займає 70% часу від всього циклу, а сам NPU переварить це за решту 30%, то ясно що основне споживання дає процSergiusTheBest: ↑ 22.03.2024 14:04Я дивився по реальним тестам, то там різниця була не сильно велика (мова йде саме про NPU вбудований в мобільний процесор) - здається десь 30%.Scoffer: ↑ 22.03.2024 13:01 Та не трохи. За оцінками гугла, їхні TPU жруть раз в 5 менше за повноціну відяху на одному і тому ж самому матричному завданні.
2. NPU зараз знаачно важливіше ніж раніше, адже всі побачили корист від ШІ, і перевели обробку на нові алгоритми, з залученням NPU. По всім зрозумілим законам, чим далі тим більша користь з цих прискорювачів, в сотні і тисячі раз, тому-що раніше було просто випрбування, а зараз вже повноцінне масове використання готового і перевіреного софту і заліза стандартизованого. Зараз у всіх на слуху всілякі TensorFlow і т.п. Це міліони годин роботи найкращих програмерів світу, але раніше цього не було, лише проби. Вже всілякі ChatGPT і т.п. засновані на їх результах.
3. Саме важливіше, ШІ це не просто код, це ціла наука, тобто найкращі, найперевіреніші ваги з певної області знань, по суті гтучна експертна система. І як досвідений спец легко, за мить, може розрізнити що краще, так і навчена мережа може це зробити в тисячі раз швидше за найкрутішу, але ненавчену. Зараз рівні готових, навчених, мереж - неймовірні, порівняно з тими що були 3-5 років тому. Тому навіть найтупіший NPU зараз може в тисячі раз більше ніж -5 років тому. Це як зарашній 3 класник знає в тисячі раз більше точних і могутніших знань ніж римський полководець
-
Yalg
Member

AMD играет в поддавки, чтобы не дай Боже не победить в рыночной войне.Scoffer: ↑ 22.03.2024 12:46 vmsolver
В АМД правлять клінічні ідіоти. Зараз на одних лише APU випускається одночасно zen2, zen3 i zen4 з вбудованими графіками GCN, RDNA2, RDNA3 i буде ще й RDNA3+. При чому періодами в самих маразматичних поєднаннях, типу Ryzen 7 7730U = zen3+GCN+7нм і це даунгрейд з райзенів 6ххх, котрі були Zen 3+ + RDNA2 + 6нм техпроцес
А потім щось з дровами не ходиться. Дійсно, з чого б?
-
SergiusTheBest
Member
- Звідки: Київ
Я більше про те, що GPU дуже схожий на NPU. Якщо їх трішки оптимізують для економії енергії - то сенсу робити окремий NPU не буде. Річ йде про звичайний користувацький сегмент. Зараз це все більше виглядає як маркетинг, щоб продати юзерам новий продукт.ronemun: ↑ 22.03.2024 23:09 1. NPU, як і будь-який прискорювач, в т.ч. графічний, майнінг, і т.п., вимагає попередньої обробки на проці, і повністю може відкритись на великих моделях, з довгим періодом розрахунку на прискорювачі, вірніше, коли час роботи проца відносно всього обрахунку мінімальний. А коли дають маленьку модель, для якої підготовка обробки на проці займає 70% часу від всього циклу, а сам NPU переварить це за решту 30%, то ясно що основне споживання дає проц
2. NPU зараз знаачно важливіше ніж раніше, адже всі побачили корист від ШІ, і перевели обробку на нові алгоритми, з залученням NPU. По всім зрозумілим законам, чим далі тим більша користь з цих прискорювачів, в сотні і тисячі раз, тому-що раніше було просто випрбування, а зараз вже повноцінне масове використання готового і перевіреного софту і заліза стандартизованого. Зараз у всіх на слуху всілякі TensorFlow і т.п. Це міліони годин роботи найкращих програмерів світу, але раніше цього не було, лише проби. Вже всілякі ChatGPT і т.п. засновані на їх результах.
3. Саме важливіше, ШІ це не просто код, це ціла наука, тобто найкращі, найперевіреніші ваги з певної області знань, по суті гтучна експертна система. І як досвідений спец легко, за мить, може розрізнити що краще, так і навчена мережа може це зробити в тисячі раз швидше за найкрутішу, але ненавчену. Зараз рівні готових, навчених, мереж - неймовірні, порівняно з тими що були 3-5 років тому. Тому навіть найтупіший NPU зараз може в тисячі раз більше ніж -5 років тому. Це як зарашній 3 класник знає в тисячі раз більше точних і могутніших знань ніж римський полководець
-
Scoffer
Member
SergiusTheBest
NPU взагалі ні разу не схожий на GPU. Всі схожості закінчуються на тому що і першому, і другому подавай швидку оперативу. Там своя особлива і ні на що інше не схожа п'янка:
GPGPU - тимчасовий костиль коли зайвих ватів ще було багато, а транзисторів мало. Зараз ми приходимо до того, що на кожне завдання потрібні свої власні прискорювачі. В осяжному майбутньому з GPU і числодробильню як клас приберуть. Власне, в мобілках її вже здебільшого прибрали.
Відправлено через 15 хвилин 20 секунд:
Та що там мобілки, аплє вже відправила openCL в статус deprecated, а metal не підтримує завдання gpgpu як такі. Тобто з ноутів теж почали прибирати.
Відеокарти нарешті повернуться до того, з чого починали - обробки графіки виключно, що не може не радувати.
NPU взагалі ні разу не схожий на GPU. Всі схожості закінчуються на тому що і першому, і другому подавай швидку оперативу. Там своя особлива і ні на що інше не схожа п'янка:
- спойлер
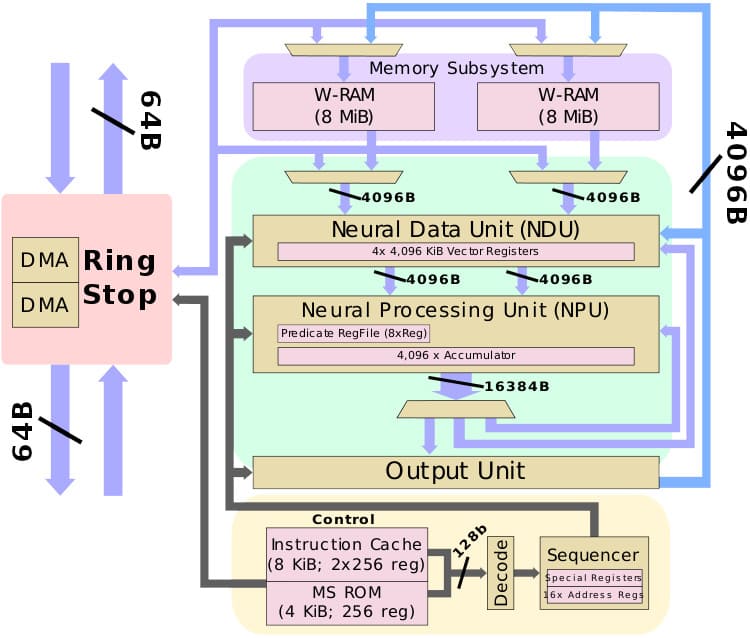
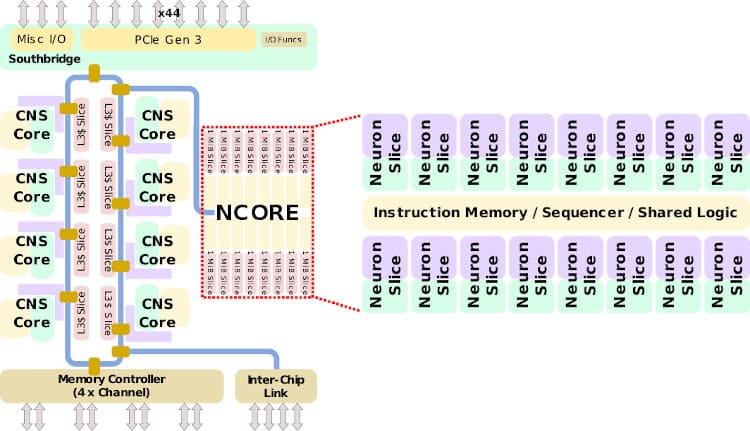
GPGPU - тимчасовий костиль коли зайвих ватів ще було багато, а транзисторів мало. Зараз ми приходимо до того, що на кожне завдання потрібні свої власні прискорювачі. В осяжному майбутньому з GPU і числодробильню як клас приберуть. Власне, в мобілках її вже здебільшого прибрали.
Відправлено через 15 хвилин 20 секунд:
Та що там мобілки, аплє вже відправила openCL в статус deprecated, а metal не підтримує завдання gpgpu як такі. Тобто з ноутів теж почали прибирати.
Відеокарти нарешті повернуться до того, з чого починали - обробки графіки виключно, що не може не радувати.
-
ronemun
Advanced Member
SergiusTheBest
Scoffer абсолютно точно пише, NPU i GPU це абсолютно різні речі, єдине що в них спільне - це транзистор і арифметика, як наука. Щось подібне було з майнінгом - відеокарти мали в сотні раз більше ядер ніж проц, дууууже простих, але цього хватало для підрахунку хешів, але все одно спеціалізовані обчислювачів хешів робили це в 10-100 раз краще за відеокарти. Просто спочатку відеокарти були доступні вже і зараз, тому їх і використали, адже спеціалізований чіп тре розробити і виготовити, а це 3 роки і міліони, а потім і сотні міліонів, чистої зелені.
Напочатку матричних обчислень було вигідно використати GPU, точніше тільки його шейдерну частину, 1/3 від усіх в GPU, для матричних обчислень. Але це було вигідно відносно звичайних проців, в разів так 30. Але і на GPU робити це глупо - чисті NPU ще в 10+ раз ефективніше при тій же кількості транзисторів і частоті
Те що нібито Нвідія розраховує на відеокартах - це такий собі обман, плутанина. ШІ можна рахувати на шедерних блоках і Нвідії і АМД, але це дуже нефективно, адже ті ж обчислення можна провести на в 10 раз меншій площі кристалу спецблоками NPU, невідволікаючи шейдери від обрахунку ігор. Саме тому в 2х00 серії ввели тензорні блоки. А у сучасних прискорювачах ШІ, типу H100, взагалі тільки самі тензорні блоки, а шейдерні, тобто прості, не матричні, обчислення, там чисто для сумісності, бо все ж таки маленька частина обчислень йде і на них.
Також графікав в іграх і т.зв. шейдери, в основному призначені тільки для FP32 (fp - плаваюча точка, 32 - це кількість бітів обчислення, буквально 32 позиції для 0 чи 1), тоді як для ШІ хватає 4 або 8 або 16 біт, а такі обчислення вимагають в 8 або 4 або 2 рази меньше транзисторів (умовно). Реально, навіщо на калькуляторі, який рахує аж 32 біт,
обчислювати те що вимагає всього 8 біт, а решту забито 0? Це ж глупо - транзистори тре, енергія виділяєтся, а толку лише на 1/4.
Теорія ШІ абсолютно не співпадає з теоріями обчслення 3д графіки, навіть якщо йде обробка графічних даних - фото чи відео. Сама обробка графіки там займає лише пару %, коли її розкладають на окремі слої, а далі як в шахматах - обчислення неймовірної кількості можливих варіантів, їх узагальнення, відокремлення і т.п., тобто суто операції логіки і аналізу, відокремлення стійких ознак і створення цифорових теорій - т.зв. мереж.
Scoffer абсолютно точно пише, NPU i GPU це абсолютно різні речі, єдине що в них спільне - це транзистор і арифметика, як наука. Щось подібне було з майнінгом - відеокарти мали в сотні раз більше ядер ніж проц, дууууже простих, але цього хватало для підрахунку хешів, але все одно спеціалізовані обчислювачів хешів робили це в 10-100 раз краще за відеокарти. Просто спочатку відеокарти були доступні вже і зараз, тому їх і використали, адже спеціалізований чіп тре розробити і виготовити, а це 3 роки і міліони, а потім і сотні міліонів, чистої зелені.
Напочатку матричних обчислень було вигідно використати GPU, точніше тільки його шейдерну частину, 1/3 від усіх в GPU, для матричних обчислень. Але це було вигідно відносно звичайних проців, в разів так 30. Але і на GPU робити це глупо - чисті NPU ще в 10+ раз ефективніше при тій же кількості транзисторів і частоті
Те що нібито Нвідія розраховує на відеокартах - це такий собі обман, плутанина. ШІ можна рахувати на шедерних блоках і Нвідії і АМД, але це дуже нефективно, адже ті ж обчислення можна провести на в 10 раз меншій площі кристалу спецблоками NPU, невідволікаючи шейдери від обрахунку ігор. Саме тому в 2х00 серії ввели тензорні блоки. А у сучасних прискорювачах ШІ, типу H100, взагалі тільки самі тензорні блоки, а шейдерні, тобто прості, не матричні, обчислення, там чисто для сумісності, бо все ж таки маленька частина обчислень йде і на них.
Також графікав в іграх і т.зв. шейдери, в основному призначені тільки для FP32 (fp - плаваюча точка, 32 - це кількість бітів обчислення, буквально 32 позиції для 0 чи 1), тоді як для ШІ хватає 4 або 8 або 16 біт, а такі обчислення вимагають в 8 або 4 або 2 рази меньше транзисторів (умовно). Реально, навіщо на калькуляторі, який рахує аж 32 біт,
обчислювати те що вимагає всього 8 біт, а решту забито 0? Це ж глупо - транзистори тре, енергія виділяєтся, а толку лише на 1/4.
Теорія ШІ абсолютно не співпадає з теоріями обчслення 3д графіки, навіть якщо йде обробка графічних даних - фото чи відео. Сама обробка графіки там займає лише пару %, коли її розкладають на окремі слої, а далі як в шахматах - обчислення неймовірної кількості можливих варіантів, їх узагальнення, відокремлення і т.п., тобто суто операції логіки і аналізу, відокремлення стійких ознак і створення цифорових теорій - т.зв. мереж.
-
SergiusTheBest
Member
- Звідки: Київ
ronemun
І там, і там все зводиться до множення матриць. А FP16 вже давно доступний для GPU.
І там, і там все зводиться до множення матриць. А FP16 вже давно доступний для GPU.