Fulkrum: ↑
05.01.2023 23:55
ДядяСаша: ↑
05.01.2023 12:23Але питання, чому не використати у процах з одним чіплетом площу, яка залишилась від невпаяного другого чіплету для, наприклад, гарного GPU тіпа 7600XT
Чиплет у Рязани около 70 мм2, площадь чипа 7600ХТ около 200мм2. Влезет максимум карта уровня 7400ХТ и та упрется в 128 бит ДДР памяти которую прийдется делить с процом.
В итоге те кому нужно играть - купят игровой проц и игровую видуху. Зачем АМД самим себе портить рынок ПК где они и процы и видухи продают? АПУ для консолей они и так миллионами отгружают.
По перше, як видно по новій презентації, мобільні APU так і вийдуть - з чіплетами Zen4, аж 2 штуки, + RDNA2 чіп. Може це буде новий IO чіп з солідною відяхою, а не те нещастя що зараз, а може взагалі окремий чіп, третій
По друге, основні блоки, які займають дуже багато місця, вже присутні в IO чіпі: контролер памяті, відеокодеки, відеовиходи. Те що вони здоровенні можете переконатись по фото чіпа Алдер/Рапідлейка. А от самі шейдерні блоки + текстури займають ну просто дууже мало місця, і прекрасно маштабуються з новим техпроцесом. Також в APU 6ї версії, 8 ядер Zen3+16МБ кешу займають стільки ж місця як 768 ядер+48текстурників+кеші RDNA2, на 6нм, і це, очевидно, меньше 70 мм.кв., які займають чіплет Zen4. Думаю на 70 мм.кв і на 5нм вміститься всі 1500 ядер, без контролера памяті і т.п.
Scoffer
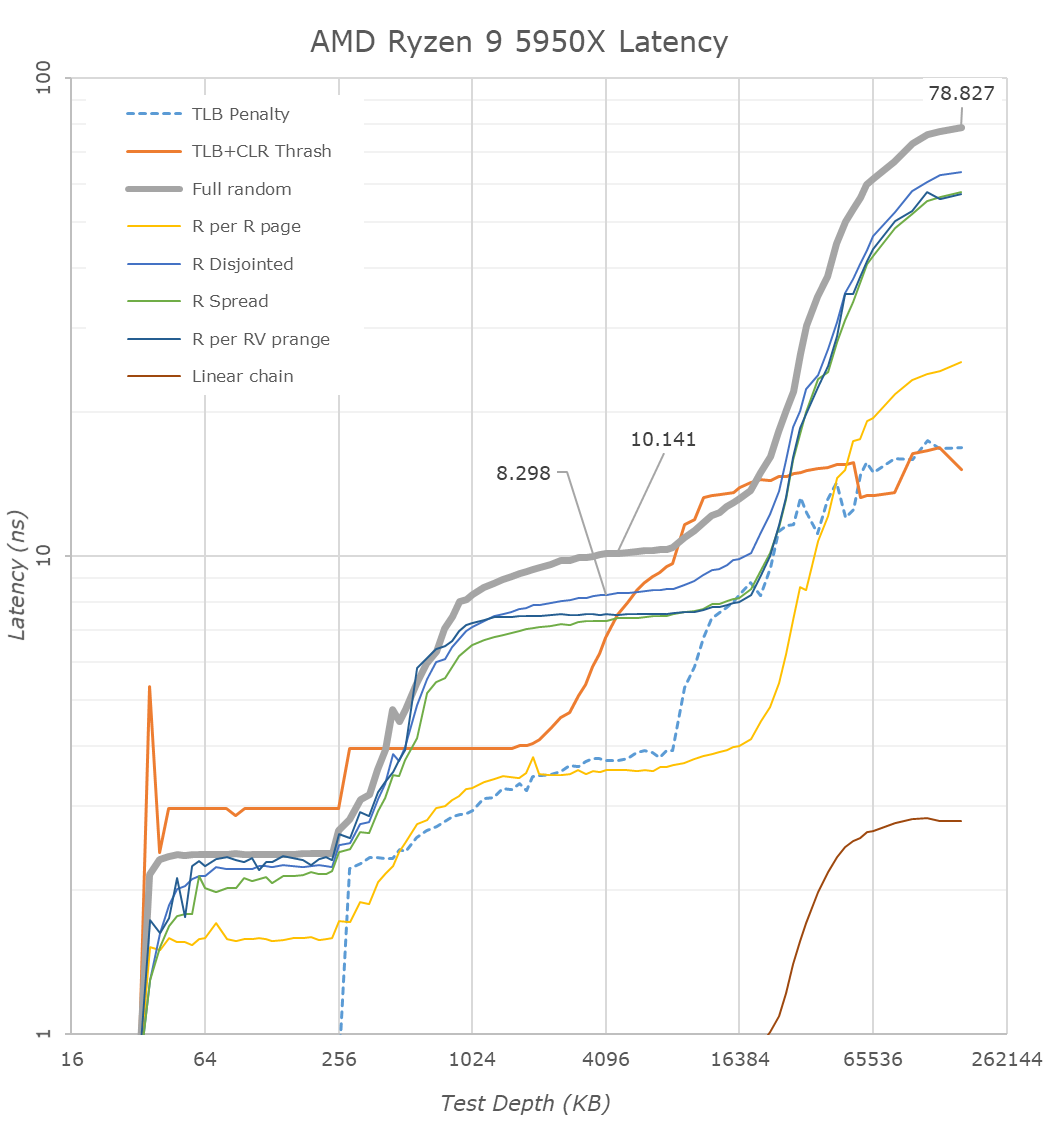
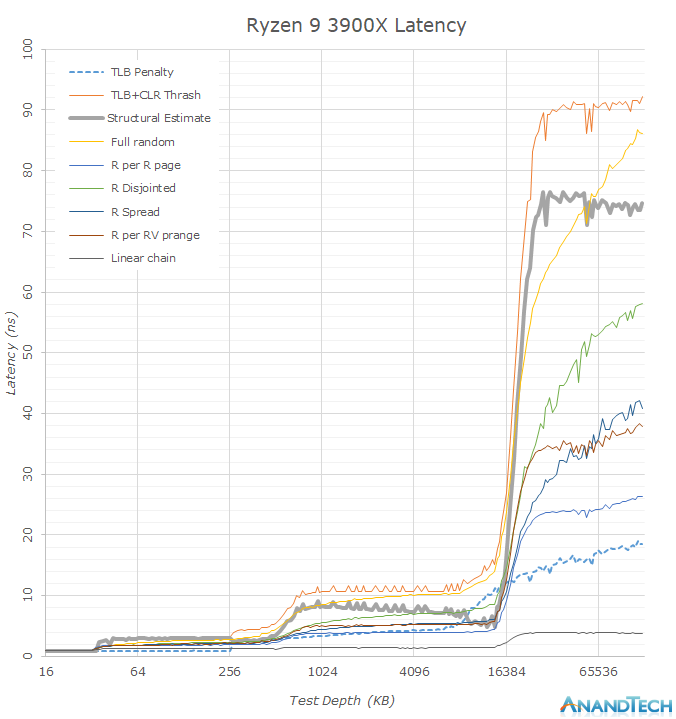
я ж не кажу що кеш туж затримку має, очевидно що вона фізично не може бути така ж. Я кажу що ніхто так жорстко не копіює дані в кешах як ти наголошуєш що вони поністю ідентичні. Якщо б так копіювали то і затримки на твоїх графіках були значно меньші. Ясно що затримка інтерконекту велика, і ясно що є часткове дублювання, але воно зараз проходить дуже високоінтелектуально, а не просто дані синхронізуються. Так в 8 чіплетних епіках взагалі б місця в кешах нехватило, а всі шини були б забиті на 100% синхронізацією. Я вже мовчу про нові 12 чіплетні. Саме тому що кеш зараз розумний тому і можна стільки ядер/потоків в один проц запхати
В наступних версіях проців і АПУ АМД, очевидно, повністю перейде на нове зєднання за прикладом Радеон 7000 з його кешами, і Instict 300, де кеш винесений до контролера памяті, на дальній рівень тобто, а ядра зі своїми кешами і gpu/gpgpu чіплети зі спільною адресацією будуть вищим рівнем