
Главное не размер
Останні статті і огляди
Новини
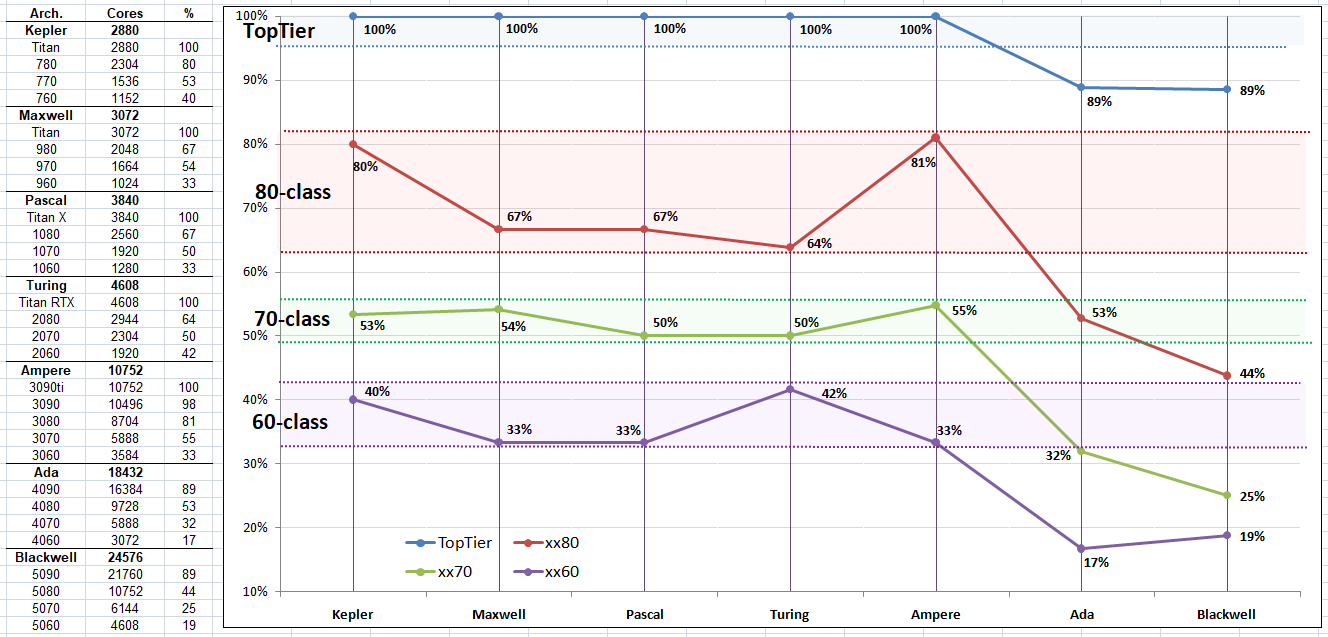
Молодші графічні процесори Nvidia Blackwell не виросли в розмірах щодо попередників
-
bes
Member
- Звідки: Kryvyi Rih
Предлагаю обсудить Молодші графічні процесори Nvidia Blackwell не виросли в розмірах щодо попередників
Главное не размер
Главное не размер
-
Megaclite
Member

Вони зменшилисьМолодші графічні процесори Nvidia Blackwell не виросли в розмірах щодо попередників
тепер 5060 буде мати 20sm замість 24
-
dead_rat
Member

- Звідки: Берлін
Нічого, відсутність росту чіпа буде скомпенсовано ростом ціни 
-
Robostyle
Member
Это то о чем я писал раньше, как хуанг будет отодвигать гейминг-гпу на задний план.
Нет, он не будет закрывать жифорс в угоду АІ, аутомотив и т.д. Он просто пустит весь кремний в высокомаржовый ИИ, а игорькам за счастье будут доставаться обрезки кожи и жира с барского стола, размером не более 300мм2
Еще повезло что GB203 не 278мм2...за 1199$
Нет, он не будет закрывать жифорс в угоду АІ, аутомотив и т.д. Он просто пустит весь кремний в высокомаржовый ИИ, а игорькам за счастье будут доставаться обрезки кожи и жира с барского стола, размером не более 300мм2
Еще повезло что GB203 не 278мм2...за 1199$
- в комментах по ссылке валялось
-
aaleksandrenko
Member

- Звідки: Житомир
AMD Ryzen 9000 має на 27% більше транзисторів чим 7000 і це не дало помітного ефекту швидкої (відсотків 5 напевно)
А тут профіт транзисторів 0, накрутили енергоспоживання і приправили намальованими кадрами. ну мрія хом'яка")
А тут профіт транзисторів 0, накрутили енергоспоживання і приправили намальованими кадрами. ну мрія хом'яка
-
Megaclite
Member
було би прикольно якби таке випустили
подивитись як лахи будуть купувати таку карту за $300, назва же потужна - RTX 5060
і №1 в стімі
-
vsx
Member

- Звідки: Kyiv
Я весь в предвкушении увидеть как 5060 догонит 4070 в 1080р.
Хотя если 5070=4090 то 5060=4080
Хотя если 5070=4090 то 5060=4080
-
ronemun
Advanced Member
4090 - 144 блоки SM - 76.3 млрд.транз.
5090 - 192 блоки SM - 92.2 млрд.транз.
Цікаво, як вони умудрились в +21% транзисторів вмістити +33% шейдерних блоків і + 33% шини памяті. При цьому блоки значно продуктивніші в матрицях, а память ggdr7 явно складніша за gddr6. Ще pcie став v5 проти v4.
Можливо на кешах зекономили
Щодо техпроцесу то це не завжди важливо - на 28 нм спочатку зробили кеплер 680 з 1532 ядра, потім кеплер Тітан 2880 ядер х32 і 960ядер х64, потім Максвелл Тітан Х 3072ядра
Відправлено через 13 хвилин 7 секунд:
але тоді ядро Zen5 має (8.3-3.0)/8=0.66 млрд. трн., а Zen4 (6.5-3.0)/8=0.44, отже Zen5 в 1.5 рази більший, недаремно ядро Zen5, саме його робоча частина, без кешу, знаачно більша ніж zen4, і це на кращому техпроцесі
рази більший, недаремно ядро Zen5, саме його робоча частина, без кешу, знаачно більша ніж zen4, і це на кращому техпроцесі
Найцікавіше виглядають ядра Zen3 - в них, з врахуванням що кеш L2=0.5МБ, виходить що ядро має всього 175-200 млн. трн., в 3+ рази меньше ніж у Zen5, а IPC меньший лише в 1.2 раз.
5090 - 192 блоки SM - 92.2 млрд.транз.
Цікаво, як вони умудрились в +21% транзисторів вмістити +33% шейдерних блоків і + 33% шини памяті. При цьому блоки значно продуктивніші в матрицях, а память ggdr7 явно складніша за gddr6. Ще pcie став v5 проти v4.
Можливо на кешах зекономили
Щодо техпроцесу то це не завжди важливо - на 28 нм спочатку зробили кеплер 680 з 1532 ядра, потім кеплер Тітан 2880 ядер х32 і 960ядер х64, потім Максвелл Тітан Х 3072ядра
Відправлено через 13 хвилин 7 секунд:
Ще цікавіше що ядра реально зросли знаачно більше, адже 32МБ кешу L3 і 8 МБ L2 залишились, а це мінімум 40*64=2,5 млрд. транзисторів. А ще є теги, десь 10% від обєму кешу, і 2 лінка IF той же. Нехай Все разом з кешами буде 3 млрдaaleksandrenko: ↑ 16.01.2025 15:47 AMD Ryzen 9000 має на 27% більше транзисторів чим 7000 і це не дало помітного ефекту швидкої (відсотків 5 напевно)
А тут профіт транзисторів 0, накрутили енергоспоживання і приправили намальованими кадрами. ну мрія хом'яка
але тоді ядро Zen5 має (8.3-3.0)/8=0.66 млрд. трн., а Zen4 (6.5-3.0)/8=0.44, отже Zen5 в 1.5
Найцікавіше виглядають ядра Zen3 - в них, з врахуванням що кеш L2=0.5МБ, виходить що ядро має всього 175-200 млн. трн., в 3+ рази меньше ніж у Zen5, а IPC меньший лише в 1.2 раз.
-
VRoman
Member
- Звідки: Albuquerque, NM, USA
Это чудо надо было назвать Ada Lovelace 2, а не Blackwell. Если я правильно помню Maxwell 2 принёс больше улучшений по сравнению с первой версией
Отправлено спустя 2 минуты 16 секунд:
Отправлено спустя 2 минуты 16 секунд:
Во всех чипах примерно так. Чего-то ненужное вырезали.ronemun: ↑ 16.01.2025 16:55 4090 - 144 блоки SM - 76.3 млрд.транз.
5090 - 192 блоки SM - 92.2 млрд.транз.
Цікаво, як вони умудрились в +21% транзисторів вмістити +33% шейдерних блоків і + 33% шини памяті. При цьому блоки значно продуктивніші в матрицях, а память ggdr7 явно складніша за gddr6. Ще pcie став v5 проти v4.
Можливо на кешах зекономили
Щодо техпроцесу то це не завжди важливо - на 28 нм спочатку зробили кеплер 680 з 1532 ядра, потім кеплер Тітан 2880 ядер х32 і 960ядер х64, потім Максвелл Тітан Х 3072ядра
-
Robostyle
Member
Ampere 3VRoman: ↑ 16.01.2025 17:23 Это чудо надо было назвать Ada Lovelace 2, а не Blackwell. Если я правильно помню Maxwell 2 принёс больше улучшений по сравнению с первой версией
-
vmsolver
Member
В Blackwell много чего поменяли, но не стоит ожидать, что это полностью новая архитектура с нуля. С нуля делают не часто, последней такой архитектурой был Тьюринг, который и привнёс аппаратное ускорение трассировки, все последующие архитектуры это допиливание первой. Со временем изменения накапливаются и становятся значительными.
Немного про Blackwell внутри, пока в общих словах, но много полезных мелочей, везде где-то да и улучшили, РТ сделали привычное удвоение, плюс много нового. Более точное и быстрое управление частотой, отключение простаивающих блоков на лету, одновременное выполнение обычных и матричных вычислений, если я верно понял, они даже распределяются по SM-ам независимо. И так далее. Это всё не заменяет документацию, которой всё ещё нет.
https://wccftech.com/nvidia-blackwell-r ... hnologies/
Я вот жду, чтобы SM, а точнее processing block-и в нём научили исполнять CUDA-ядрами на выбор одну из двух инструкций, какую из этих двух исполняет то или иное CUDA-ядро зависит от маски, таким методом можно будет исполнять обе ветки условного ветвления одновременно. В Аде такое ждал, не дождался, посмотрим что скажет Blackwell по этому поводу")
Немного про Blackwell внутри, пока в общих словах, но много полезных мелочей, везде где-то да и улучшили, РТ сделали привычное удвоение, плюс много нового. Более точное и быстрое управление частотой, отключение простаивающих блоков на лету, одновременное выполнение обычных и матричных вычислений, если я верно понял, они даже распределяются по SM-ам независимо. И так далее. Это всё не заменяет документацию, которой всё ещё нет.
https://wccftech.com/nvidia-blackwell-r ... hnologies/
Я вот жду, чтобы SM, а точнее processing block-и в нём научили исполнять CUDA-ядрами на выбор одну из двух инструкций, какую из этих двух исполняет то или иное CUDA-ядро зависит от маски, таким методом можно будет исполнять обе ветки условного ветвления одновременно. В Аде такое ждал, не дождался, посмотрим что скажет Blackwell по этому поводу