
После микрокода 0x129 и 0x12B при включенном профиле Intel Default Settings некоторые модели процессоров 13/14 поколения сбрасывают PL2 на PL1 через 10 секунд нагрузки и больше его не подымают. А на реддите можно найти жалобы на такое поведение и до обновления прошивок.Earanak: ↑ 08.10.2024 22:21 Сейчас же на актуальных процах запускаешь рендер, и сразу работает PL2 лимит и так хоть через 10 часов он остается на месте, в том числе и вольтаж/частоты не проседают.
Останні статті і огляди
Новини
Підтверджено характеристики настільних процесорів Intel Core Ultra 200
-
Sergey Lander
Junior

- Звідки: Украина
Востаннє редагувалось 09.10.2024 01:06 користувачем Sergey Lander, всього редагувалось 1 раз.
-
Earanak
Member

- Звідки: Украина
Sergey Lander, на Z790 Tomahawk DDR4 и 13900KF у меня такого не происходит на крайней версии Биоса с включенным Intel Default пресетом. 10 секунд это явно не TAU, какой то другого рода косяк, слишком быстро для TAU, который в большинстве случаев в диапазоне от 56 до 128 секунд. Может это уже вмешательство вендоров плат в этот нюанс, не сталкивался с таким. Настройка то эта была и на старых биосах и в XTU тоже, но была неактивной по-умолчанию. Биос с 0х12B только вчера вышел под мою плату. Пока никаких отличий не заметил относительно 0х129. Бенчи выдают +/- то же самое. VID-запросы в простое/легких нагрузках те же что были, видать без осциллографа впаянного в сокет и не понять что там чет изменилось 
Востаннє редагувалось 09.10.2024 01:25 користувачем Earanak, всього редагувалось 2 разів.
-
Kassatka
Member

- Звідки: Курник під Києвом
someoneNicko: ↑ 08.10.2024 19:51 А якби я був Адміном, я би зробив так, щоби користувач не міг зробити дурниці. Поганий UX -- вина сайту
Зате сайт Overclockers.ua чудово повнофункціонально працює під Windows XP, а таким на сьогодні катастрофічно мало сайтів похвалитися можуть.
-
Sergey Lander
Junior
- Звідки: Украина
Судя по жалобам, с этим столкнулись владельцы non-K процессоров на B660/760. За два года баг не устранили. Нужно вручную повышать PL1 до PL2 или параллельно с Intel Default пресетом включать пресет вендора платы.Earanak: ↑ 09.10.2024 01:05 на Z790 Tomahawk DDR4 и 13900KF у меня такого не происходит на крайней версии Биоса с включенным Intel Default пресетом. Наверное это уже вмешательство вендоров плат в этот нюанс.
https://www.reddit.com/r/intel/comments ... re_clocks/
https://www.reddit.com/r/intel/comments ... above_tdp/
-
Earanak
Member
- Звідки: Украина
Sergey Lander, ну так очевидно что это баг а не механизм который мы обсуждали на прошлой странице.
Еще и специфический как вы сказали - для конкретного чипсета, модели процессоров и микрокода...
К тому же срабатывающий с ваших слов спустя 10 секунд, что намного быстрее чем классический TAU
Еще и специфический как вы сказали - для конкретного чипсета, модели процессоров и микрокода...
К тому же срабатывающий с ваших слов спустя 10 секунд, что намного быстрее чем классический TAU
-
ronemun
Advanced Member
що забули де в браузері кнопка назад?daesz: ↑ 08.10.2024 18:18 Люди сидять на форумі 13 років і все ще видаляють посилання з першого посту.
або Alt+стрілка вліво
також в самому вверху зліва є сама перша силка Overclockers.ua яка відкриє головну сторінку з новинами
Відправлено через 1 годину 13 хвилин 56 секунд:
0. це збільшення з 12+2 станцій до 14+2. На кільці також відяха+медіакодер+контролер дисплеїв, не така вже й потрібна всім фіча в десктопі, а якщо опціонально тре то могли б окремо приліпити кристал на 4 лінії PCIe v5 (16Гбайт/с в кожну сторону - це як у geforce 2080Ti), все одно зараз це окремий чіп як в Lunarlake, 25 мм2 займає, добавили б 2х32 gddr6 поруч, заодно основний контролер памяті розрузили б для cpu-ядер, а то 2 канали там вже явно мало.Yaroslav308: ↑ 09.10.2024 00:25Судя по всему, это адекватный предел для кольцевой шины. Иначе они бы не объединяли e-ядра в кластеры по 4 с одной остановкой, а в серверах не делали сначала пару колец, а потом и сетку.ronemun: ↑ 08.10.2024 17:40Невже було шкода добавити ще 4-8 ядер (7,5-15мм2)
1. так вони тепер відмовились від мультипотоку, тож на 8 потоків p-core меньше, а саме синхронізація кешів пропорційна кількості потоків.
2. Також зараз вони найчастіші передачі між ядрами зменшили - помістили е-ядра між p-ядрами, це силно зменшило кількість кроків по кільцю від p до е-ядер
3. збільшення кешу L3 до 4-6 МБ на ядро знаачно зменшить необхідність скакати по кільцю при нестачі найближчої банки. Зараз кеш займає 0,35 мм2 на 1Мбайт. Заодно зменшиться необхідність передвати дані по кільцю в/з контролер памяті якщо L3 не хватає
4. в P-ядер кеш L2 тепер аж 3МБ, по суті на ядро є 3L2+3L3, ну і сусідні 3+3, ті що біля е-core, якщо вільні, в межах 1 передачі.
5. В АМД IO хаб в EPYC обслуговує 6x2 чіплети по 8/16 ядер, 8 коренів PCIe x16 v5, 6x2канальних DDR5, ну і свій хаб і т.п. Тож 14 станцій в десктопі це взагалі не проблема
6. для любителів рендеру могли б випустити чіп де 2 p-core замінено на 8 e-core. Зараз p-core вже не такі важливі - немає HT і частота зменшилась до 5.3, IPC виріст всього на 9%, а e-core навпаки - IPC зріс на 35/65% в цілих/плаваючих чисел, а частота зросла до 4,6 по замовчуванню на всі 16 e-core
-
waryag
Member

- Звідки: Суми
Як допоможе кнопка назад, якщо на новину перейшли з конференції?ronemun: ↑ 09.10.2024 10:36що забули де в браузері кнопка назад?
або Alt+стрілка вліво
також в самому вверху зліва є сама перша силка Overclockers.ua яка відкриє головну сторінку з новинами
І взагалі, навіщо робити зайві дії по видаленню шапки?
-
ronemun
Advanced Member
waryag
вибачаюсь, так вийшло")
вибачаюсь, так вийшло
-
evgeniyproweb
Member

- Звідки: Zaporizhzhya
Kassatka: ↑ 09.10.2024 01:18someoneNicko: ↑ 08.10.2024 19:51 А якби я був Адміном, я би зробив так, щоби користувач не міг зробити дурниці. Поганий UX -- вина сайту
Зате сайт Overclockers.ua чудово повнофункціонально працює під Windows XP, а таким на сьогодні катастрофічно мало сайтів похвалитися можуть.
Мені в 2021 це дуже стало в нагоді, коли основний комп здох і по факту ніде було інтернетом користуватися.
есть такое, это потому что у XP к примеру гугл хром не обновишь до последней версии насколько помню, там есть предел до какой то версии, а значит все то новое что пришло в последующих версиях и которое используют веб разработчики он не понимает, поэтому и плывут сайты в которых уже юзают современный код без оглядки на тот же IE6 и т.д.
-
alexeygalas
Member

- Звідки: Україна Хмельницький
MyPal на базі Firefox дуже хороший браузер з сучсним SSL. Використовую на ретрокорчі.evgeniyproweb: ↑ 09.10.2024 11:15есть такое, это потому что у XP к примеру гугл хром не обновишь до последней версии насколько помню, там есть предел до какой то версии, а значит все то новое что пришло в последующих версиях и которое используют веб разработчики он не понимает, поэтому и плывут сайты в которых уже юзают современный код без оглядки на тот же IE6 и т.д.
Є ще Supermium на базі Google Chromium але дуже тупить
-
evgeniyproweb
Member
- Звідки: Zaporizhzhya
погуглил, даже не слышал за них, буду знать шо есть подобное )))alexeygalas: ↑ 09.10.2024 11:25MyPal на базі Firefox дуже хороший браузер з сучсним SSL. Використовую на ретрокорчі.evgeniyproweb: ↑ 09.10.2024 11:15есть такое, это потому что у XP к примеру гугл хром не обновишь до последней версии насколько помню, там есть предел до какой то версии, а значит все то новое что пришло в последующих версиях и которое используют веб разработчики он не понимает, поэтому и плывут сайты в которых уже юзают современный код без оглядки на тот же IE6 и т.д.
Є ще Supermium на базі Google Chromium але дуже тупить
-
vmsolver
Member
Не существует никакого "L3 на ядро", "ближайшей банки L3", "недостатка ближайшей банки" и так далее, эти мифы у вас постоянно повторяются. L3 это распределённый кеш, все его "банки" (слайсы) работают на все ядра и не привязаны ни какому ядру, информация в кеше L3 размазана по всем банкам сразу, даже если она была вытеснена из одного ядра, информация всегда размещается в разных банках для увеличения IO-rate. Все запросы идут всегда во все слайсы по кольцу, потому что не известно в каком слайсе L3 будет нужная информация.ronemun: ↑ 09.10.2024 10:363. збільшення кешу L3 до 4-6 МБ на ядро знаачно зменшить необхідність скакати по кільцю при нестачі найближчої банки. Зараз кеш займає 0,35 мм2 на 1Мбайт. Заодно зменшиться необхідність передвати дані по кільцю в/з контролер памяті якщо L3 не хватає
4. в P-ядер кеш L2 тепер аж 3МБ, по суті на ядро є 3L2+3L3, ну і сусідні 3+3, ті що біля е-core, якщо вільні, в межах 1 передачі.
У кольца нет проблемы латентности, у кольца есть проблема полосы.
-
daesz
Member

Назад куди? На форум? Надіюсь додать в правила "видалення посилання на новину - read only на місяць із збільшенням по геометричній прогресії за кожне наступне порушення".ronemun: ↑ 09.10.2024 10:36що забули де в браузері кнопка назад?daesz: ↑ 08.10.2024 18:18 Люди сидять на форумі 13 років і все ще видаляють посилання з першого посту.
або Alt+стрілка вліво
також в самому вверху зліва є сама перша силка Overclockers.ua яка відкриє головну сторінку з новинами
-
ronemun
Advanced Member
daesz
як куди? якщо ви перейшли з новини на форум, то кнопка назад вас і поверне на новину.
А силка Overclockers.ua поверне на головну сторінку, де й та новина, і інші.
Але я погоджуюсь, що бажана силка напряму на новину.
Тільки я взагалі НІКОЛИ такого не бачив, щоб ця силка була в 1му повідомленні, та ще й в такому форматі що змішується з самим обговоренням.
У всіх просто формується сторінка яка автоматично окремо має і назву, і силку, і суть теми: обговорення новини, і інші автоматичні атрибути, в .т.ч закріплена, закінчена, і т.п.
А то так виходить що я пропоную обговорення новини, але в реалі я просто хочу почути думки інших, тих хто в темі, в т.ч. насмішників і посміятись з ними, почути доповнення до новини, адже переважно новина дуууже поверхнева, і далі розвинути думку: запитатись те що неясно, виразити своє враження
Ну і ще одне, я помічав що 1ше повідомлення має просто непристойну кількість мінусів. Просто тому що всі хто зайдуть на ньому витискають своє серце (душу-центральна система емоцій і відчуттів), підсвідомо, і це весело ))) Ніщо так не цінується як ЩИРІСТЬ.
vmsolver
ясно що L3 - це для всіх, а L2 - для себе.
Але доступ до банок не паралельний, а послідовни, бо це кільце!
у Інтел завжди банка L3 навпроти ядра - доступ всього +1 такт, а сусідні - ще +7 тактів, і так по кругу в різні сторони.
L3 має затримку в тестах 15нс, але це В СЕРЕДНЬОМУ, враховуючи ВЕСЬ кеш, всі банки, +дальні банки, 6+ станцій в кожну сторону, до 6*87=42 тактів=+10 нс на частоті кільця 4 ГГц (звичайно це меньше ніж +65-130 нс в оперативу в одну сторону, 130-260 в обидві сторони). А ближня банка тоді 8 нс, а найдальша 8+42/4=18. А +10нс це 50 тактів при 5 ГГц. Різниця очевидна. Тоді як L2 всього 3-4 нс, залежно від частоти.
Але своя банка найбільш вільна, бо кожен має свою, а це аж 3Мбайт на банку, і щоб її зчитати/записати по 32 Байт/с тре аж 100 тисяч тактів
Тому і банки L3, які знаходяться по сусідству стають своїми, якщо не зайняті - я ж про це і пишу!!!. якщо не зайняті. Згідно політики планувальника при супер крутих нагрузках планувальник Інтел автоматично перекине все з e-ядра на p-ядро, а в ArrowLake тепер це сусіди, тож L3 навпроти e-ядер будуть вільні, в теорії.
В АМД Zen5 всього 1 МБ кешу L2, і він моментально переповниться при високій частоті і задачах на 256+ біт, тим більше при 512 біт. Тим більше зараз, коли затримка памяті - 100+ нс.
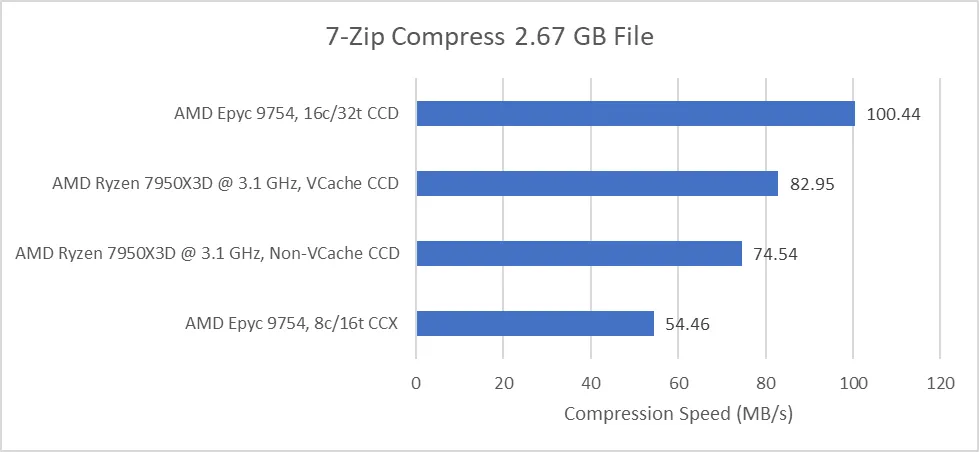
Є реальні тести, де в 7zip Zen4@3,1GHz 8ядер/8потоків (без HT) і при 16МБ L3 в 1.4 рази програвав тому ж Zen4 з 32 Мбайт. Навіть якщо в 6 раз більше каналів DDR5 (Epyc проти Ryzen) !!!. Так зааз важлива затримка, тим більше 8 p-ядер/16 потоків Zen5 чи Intel LionCove на 5,5 ГГц, тож сусідні банки дуже важливі якщо своя навпроти заповнена
як куди? якщо ви перейшли з новини на форум, то кнопка назад вас і поверне на новину.
А силка Overclockers.ua поверне на головну сторінку, де й та новина, і інші.
Але я погоджуюсь, що бажана силка напряму на новину.
Тільки я взагалі НІКОЛИ такого не бачив, щоб ця силка була в 1му повідомленні, та ще й в такому форматі що змішується з самим обговоренням.
У всіх просто формується сторінка яка автоматично окремо має і назву, і силку, і суть теми: обговорення новини, і інші автоматичні атрибути, в .т.ч закріплена, закінчена, і т.п.
А то так виходить що я пропоную обговорення новини, але в реалі я просто хочу почути думки інших, тих хто в темі, в т.ч. насмішників і посміятись з ними, почути доповнення до новини, адже переважно новина дуууже поверхнева, і далі розвинути думку: запитатись те що неясно, виразити своє враження
Ну і ще одне, я помічав що 1ше повідомлення має просто непристойну кількість мінусів. Просто тому що всі хто зайдуть на ньому витискають своє серце (душу-центральна система емоцій і відчуттів), підсвідомо, і це весело ))) Ніщо так не цінується як ЩИРІСТЬ.
vmsolver
ясно що L3 - це для всіх, а L2 - для себе.
Але доступ до банок не паралельний, а послідовни, бо це кільце!
у Інтел завжди банка L3 навпроти ядра - доступ всього +1 такт, а сусідні - ще +7 тактів, і так по кругу в різні сторони.
L3 має затримку в тестах 15нс, але це В СЕРЕДНЬОМУ, враховуючи ВЕСЬ кеш, всі банки, +дальні банки, 6+ станцій в кожну сторону, до 6*87=42 тактів=+10 нс на частоті кільця 4 ГГц (звичайно це меньше ніж +65-130 нс в оперативу в одну сторону, 130-260 в обидві сторони). А ближня банка тоді 8 нс, а найдальша 8+42/4=18. А +10нс це 50 тактів при 5 ГГц. Різниця очевидна. Тоді як L2 всього 3-4 нс, залежно від частоти.
Але своя банка найбільш вільна, бо кожен має свою, а це аж 3Мбайт на банку, і щоб її зчитати/записати по 32 Байт/с тре аж 100 тисяч тактів
Тому і банки L3, які знаходяться по сусідству стають своїми, якщо не зайняті - я ж про це і пишу!!!. якщо не зайняті. Згідно політики планувальника при супер крутих нагрузках планувальник Інтел автоматично перекине все з e-ядра на p-ядро, а в ArrowLake тепер це сусіди, тож L3 навпроти e-ядер будуть вільні, в теорії.
В АМД Zen5 всього 1 МБ кешу L2, і він моментально переповниться при високій частоті і задачах на 256+ біт, тим більше при 512 біт. Тим більше зараз, коли затримка памяті - 100+ нс.
Є реальні тести, де в 7zip Zen4@3,1GHz 8ядер/8потоків (без HT) і при 16МБ L3 в 1.4 рази програвав тому ж Zen4 з 32 Мбайт. Навіть якщо в 6 раз більше каналів DDR5 (Epyc проти Ryzen) !!!. Так зааз важлива затримка, тим більше 8 p-ядер/16 потоків Zen5 чи Intel LionCove на 5,5 ГГц, тож сусідні банки дуже важливі якщо своя навпроти заповнена
{kind=link}
-
daesz
Member
Ще раз - я перейшов з форума в тему обговорень, головну сторінку сайту відкриваю "раз в пятирічку", та й то тільки коли потрібно знайти якийсь старий огляд чи новину.ronemun: ↑ 09.10.2024 16:00 daesz
як куди? якщо ви перейшли з новини на форум, то кнопка назад вас і поверне на новину.
А силка Overclockers.ua поверне на головну сторінку, де й та новина, і інші.
Але я погоджуюсь, що бажана силка напряму на новину.
Тільки я взагалі НІКОЛИ такого не бачив, щоб ця силка була в 1му повідомленні, та ще й в такому форматі що змішується з самим обговоренням.
У всіх просто формується сторінка яка автоматично окремо має і назву, і силку, і суть теми: обговорення новини, і інші автоматичні атрибути, в .т.ч закріплена, закінчена, і т.п.
А то так виходить що я пропоную обговорення новини, але в реалі я просто хочу почути думки інших, тих хто в темі, в т.ч. насмішників і посміятись з ними, почути доповнення до новини, адже переважно новина дуууже поверхнева, і далі розвинути думку: запитатись те що неясно, виразити своє враження
Ну і ще одне, я помічав що 1ше повідомлення має просто непристойну кількість мінусів. Просто тому що всі хто зайдуть на ньому витискають своє серце (душу-центральна система емоцій і відчуттів), підсвідомо, і це весело ))) Ніщо так не цінується як ЩИРІСТЬ.
Воно має непристойну кількість мінусів - бо ви з теми в тему продовжуєте видаляти лінк на саму новину
-
dext
Member
- Звідки: Dnipro
Ні, латентність прямо залежить (збільшується) при збільшенні датасету тобто дані 100% локалізуються в найближчих банках/слайсах до ядра, яке цими даними оперуєvmsolver: ↑ 09.10.2024 13:40 информация в кеше L3 размазана по всем банкам сразу, даже если она была вытеснена из одного ядра, информация всегда размещается в разных банках для увеличения IO-rate. Все запросы идут всегда во все слайсы по кольцу, потому что не известно в каком слайсе L3 будет нужная информация.
-
vmsolver
Member
Латентность увеличивается при увеличении датасета потому что он перестаёт влезать в L1, а потом и в L2, поэтому латентность сначала низкая, а потом повышается, если рассматривать механизм работы только L3, то данные размазываются по всем слайсам, так как это распределённый кеш, кольцо сшивает все слайсы в единый L3 и никакая его часть не принадлежит какому-то ядру. Данные вытесненные из ядра тоже распределяются по всем слайсам с некоторой гранулярностью.dext: ↑ 09.10.2024 16:28 Ні, латентність прямо залежить (збільшується) при збільшенні датасету тобто дані 100% локалізуються в найближчих банках/слайсах до ядра, яке цими даними оперує
Миф про принадлежность слайсов L3 к какому-то ядру тут норма, и я давно пытаюсь его отсюда вывести. Пока бесполезно, но я буду стойким
-
ronemun
Advanced Member
daesz
та добре вже, я повністю згодився з вами ще пару постів вище.
Я був втомлений і при виправленні свого повідомлення, чисто нажав Ctrl+A (виділити все) і випадково стер весь текст разом з силкою
Але якщо дивитись уважно, буквально над цим є назва теми, з точно такою ж назвою як в 1му пості - нехай туди і прикрутять силку.
та добре вже, я повністю згодився з вами ще пару постів вище.
Я був втомлений і при виправленні свого повідомлення, чисто нажав Ctrl+A (виділити все) і випадково стер весь текст разом з силкою
Але якщо дивитись уважно, буквально над цим є назва теми, з точно такою ж назвою як в 1му пості - нехай туди і прикрутять силку.
-
vmsolver
Member
Нет никакой своей банки, все банки заполняются более-менее равномерно. Все слайсы кеша работают на кольцо, все ядра подключены к кольцу, вот так это работает, информация с ядра не записывается в ближайший слайс, а распределяется по всем слайсам, какая-то часть конечно же попадает в ближайший, наравне с другими.ronemun: ↑ 09.10.2024 16:00Але своя банка найбільш вільна
Интерконнект это 2нс максимум, в среднем можно считать 1нс, это биение латентности распределённого кеша, совсем не много, зато он гораздо больше чем один слайс, неплохо масштабируется, имеет огромный IO-rate по сравнению с одним слайсом и т.д. L3 спроектирован для работы на много ядер, поэтому все слайсы должны работать на все ядра, даже если в один момент работает одно ядро, механизм работы от этого не меняется.
-
ronemun
Advanced Member
vmsolver
кільце - послідовна структура, ане паралельна, де чим більше - тим краще. Тут навпаки - чим більше кроків - тим гірше.
Якщо ви почнете переносити дані по всім слайсам - швидкість не збільшиться, а навпаки, зменшиться, навіть для 1го ядра, не те що всіх. Адже це займе такти шини (кільця), але в пустоту, бо це просто передача, а дані лише віддаляться від виконавця, а основний закон каже що вони мають бути якомога ближче. Також зайнятий такт шини одним ядром забере цей же такт в іншого, і сумарна швидкість шини впаде пропорційно кількості кроків (в середньому)
Звичайно, коли найближчі банки заповнені, то тре передавати далі, але там діють теорії які нам навітьне снились, зі своїми механізами.
Заповнення дальніх банок можливе якщо є інформація про їх вільне місце в найближчому агенті, тобто дані про це вже передані перед тим.
Але якщо всі ядра загружені, ще й 2 потоки на ядро, і переповення кешу L2, та ще й всі щось пишуть/читають з памяті, та ще й між собою синхронізують - там маса проблем
По суті, замість розмазувати дані 1го потоку по всьому кешу, краще його зконцентрувати біля того ядра, де він виконується, а якщо це місце зайняте іншим потоком з іншого ядра, то саме ці дані передати ближче до того ядра, тобто просто пересортувати дані. Або, якщо даних надто багато - то й сам потік (контекст) перенести, звільнивша ядро для потоку дані якого вже тут. Але це вже задачі спеців, я лише здалека малюю.
Враховуючи, що ядро Zen4c на 5нм займає всього 1,6 мм2, то взагалі немає сенсу про це говорити - кремній (пластини) для міліонів ядер коштує лише тисячні долі від коштів вкладених в розробку. Самі можете підрахувати для 30 см пластини
кільце - послідовна структура, ане паралельна, де чим більше - тим краще. Тут навпаки - чим більше кроків - тим гірше.
Якщо ви почнете переносити дані по всім слайсам - швидкість не збільшиться, а навпаки, зменшиться, навіть для 1го ядра, не те що всіх. Адже це займе такти шини (кільця), але в пустоту, бо це просто передача, а дані лише віддаляться від виконавця, а основний закон каже що вони мають бути якомога ближче. Також зайнятий такт шини одним ядром забере цей же такт в іншого, і сумарна швидкість шини впаде пропорційно кількості кроків (в середньому)
Звичайно, коли найближчі банки заповнені, то тре передавати далі, але там діють теорії які нам навітьне снились, зі своїми механізами.
Заповнення дальніх банок можливе якщо є інформація про їх вільне місце в найближчому агенті, тобто дані про це вже передані перед тим.
Але якщо всі ядра загружені, ще й 2 потоки на ядро, і переповення кешу L2, та ще й всі щось пишуть/читають з памяті, та ще й між собою синхронізують - там маса проблем
По суті, замість розмазувати дані 1го потоку по всьому кешу, краще його зконцентрувати біля того ядра, де він виконується, а якщо це місце зайняте іншим потоком з іншого ядра, то саме ці дані передати ближче до того ядра, тобто просто пересортувати дані. Або, якщо даних надто багато - то й сам потік (контекст) перенести, звільнивша ядро для потоку дані якого вже тут. Але це вже задачі спеців, я лише здалека малюю.
Враховуючи, що ядро Zen4c на 5нм займає всього 1,6 мм2, то взагалі немає сенсу про це говорити - кремній (пластини) для міліонів ядер коштує лише тисячні долі від коштів вкладених в розробку. Самі можете підрахувати для 30 см пластини
Востаннє редагувалось 09.10.2024 18:21 користувачем ronemun, всього редагувалось 2 разів.