
Пропоную обговорити У суперкомп'ютері Nvidia DGX GH200 об'єднано 256 суперчипів Grace Hopper
Было: IBM vs Cray. Стало: IBM vs Cray vs Nvidia.
Чем быстрее игроделы избавятся от технологий Nvidia в играх, заточенных только под Nvidia чипы, тем лучше будет для всех: как игроделов, так и покупателей/игроков.
Останні статті і огляди
Новини
У суперкомп'ютері Nvidia DGX GH200 об'єднано 256 суперчипів Grace Hopper
-
Keyser Soze
Member
-
Firebrand
Member

- Звідки: Киев
Keyser Soze: ↑ 29.05.2023 11:58Чем быстрее игроделы избавятся от технологий Nvidia в играх, заточенных только под Nvidia чипы, тем лучше будет для всех: как игроделов, так и покупателей/игроков.
-
seraphic
Member

- Звідки: Дон.обл
а если ещё игроделы избавятся от зависимости к мелкософту?
-
Scoffer
Member

Ну все таки не спільної, а сумарної. Один Grace Hopper напряму не адресує пам'ять іншого Grace Hopper.144 терабайти спільної пам'яті
-
MetalistForever
Member

- Звідки: Харьков
Мощно , мощно .... А когда HBM3 в массы пойдет , для обычных геймеров ?
-
EvhenS
Member

- Звідки: Черкаси
MetalistForever
Яке НВМ3. Тут молитися треба щоб в 5060 за 500$ 8Гб gddr 6x на 64 бітній шині не припаяли.
Яке НВМ3. Тут молитися треба щоб в 5060 за 500$ 8Гб gddr 6x на 64 бітній шині не припаяли.
-
vmsolver
Member
Адресует, вся система это логически один большой GPU.Scoffer: ↑ 29.05.2023 13:37Ну все таки не спільної, а сумарної. Один Grace Hopper напряму не адресує пам'ять іншого Grace Hopper.144 терабайти спільної пам'яті
-
Scoffer
Member
vmsolver
Якраз от і ні. Це кластер з 256 нод, з'єднаних сіточкою. Кожна нода - незалежний сервер з окремою своєю ОС і своїми ресурсами. Доступ до чужих ресурсів відсутній. Обмін інформацією з чужими ОС через Message Passing Interface. Класичний MPP-суперкомп'ютер.
Поверх кластеру на вибір користувача-експлуатанта запускається розподілений обчислювальний софт на базі OpenACC або OpenMP.
Власне, з логічної точки зору схема нічим не відрізняється від того що ти б зібрав 256 стандартних рекових сервачків, тільки незрівнянно компактніша.
Відправлено через 19 хвилин 2 секунди:
Розігнався ти на GPU зі 144 терами оперативи Ні, кожен окремо взятий GPU має доступ до своїх 96 гіг HBM і на тому все.
Ні, кожен окремо взятий GPU має доступ до своїх 96 гіг HBM і на тому все.
Якраз от і ні. Це кластер з 256 нод, з'єднаних сіточкою. Кожна нода - незалежний сервер з окремою своєю ОС і своїми ресурсами. Доступ до чужих ресурсів відсутній. Обмін інформацією з чужими ОС через Message Passing Interface. Класичний MPP-суперкомп'ютер.
Поверх кластеру на вибір користувача-експлуатанта запускається розподілений обчислювальний софт на базі OpenACC або OpenMP.
Власне, з логічної точки зору схема нічим не відрізняється від того що ти б зібрав 256 стандартних рекових сервачків, тільки незрівнянно компактніша.
Відправлено через 19 хвилин 2 секунди:
Розігнався ти на GPU зі 144 терами оперативи
-
vmsolver
Member
Scoffer
Хуанг говорил что это всё один GPU, и на слайдах тоже это было написано, хватит фантазировать уже, у них и первые DGX логически один GPU с единой адресацией, а весь этот суперкомп является DGX следующего поколения. Смысл им делать быстрый интерконнект, чтобы просто всем сказать что использовать его нельзя? Нет, быстрый интерконнект нужен для сшивки всех ресурсов в логически единый GPU.
Каждый GPU имеет доступ ко всему объему памяти, только в локальный буфер полоса выше (полоса HBM3), во все остальные медленнее (линк 900 ГБ/с), но адресное пространство единое.
Відправлено через 2 хвилини 32 секунди:
На тебе из первоисточника
Хуанг говорил что это всё один GPU, и на слайдах тоже это было написано, хватит фантазировать уже, у них и первые DGX логически один GPU с единой адресацией, а весь этот суперкомп является DGX следующего поколения. Смысл им делать быстрый интерконнект, чтобы просто всем сказать что использовать его нельзя? Нет, быстрый интерконнект нужен для сшивки всех ресурсов в логически единый GPU.
Каждый GPU имеет доступ ко всему объему памяти, только в локальный буфер полоса выше (полоса HBM3), во все остальные медленнее (линк 900 ГБ/с), но адресное пространство единое.
Відправлено через 2 хвилини 32 секунди:
На тебе из первоисточника
Giant Memory for Giant Models
Unlike existing AI supercomputers that are designed to support workloads
that fit within the memory of a single system, NVIDIA DGX GH200 is the only
AI supercomputer that offers a shared memory space of up to 144TB across 256
Grace Hopper Superchips, providing developers with nearly 500X more fast-access
memory to build massive models. DGX GH200 is the first supercomputer to pair
Grace Hopper Superchips with the NVIDIA NVLink Switch System, which allows up
to 256 GPUs to be united as one data-center-size GPU. This architecture provides
48X more bandwidth than the previous generation, delivering the power of a
massive AI supercomputer with the simplicity of programming a single GPU.
-
Scoffer
Member
vmsolver
Подивився опис архітектури, дійсно додали можливість шарити пам'ять. Але 900 ГБ/с це ні про що, це 15 серверних планок ддр5. У однієї-єдиної RTX 4090 ПСП вище. Тобто як до дупи дверцята. На практиці працюватиме воно як традиційний MPI/MPP суперкомп.
Часи SMP архітектур в суперкомп'ютерах закінчились в 90х, не масштабуються вони, Крей не дасть збрехати, тримався до останнього, перейшов з кремнія на арсенід галія, і зрештою навіть він здався.
Подивився опис архітектури, дійсно додали можливість шарити пам'ять. Але 900 ГБ/с це ні про що, це 15 серверних планок ддр5. У однієї-єдиної RTX 4090 ПСП вище. Тобто як до дупи дверцята. На практиці працюватиме воно як традиційний MPI/MPP суперкомп.
Часи SMP архітектур в суперкомп'ютерах закінчились в 90х, не масштабуються вони, Крей не дасть збрехати, тримався до останнього, перейшов з кремнія на арсенід галія, і зрештою навіть він здався.
-
vmsolver
Member
Scoffer
Это не "дали возможность" эта фишка системы, они именно для этого такой мощный интерконнект делали. Не говори ерунды, 900 ГБ/с между любыми GPU в системе это много, считалкины как дети малые будут радоваться новой игрушке, её возможностям и удобству единой системы. Нет это не традиционный MPP суперкомп, не спорь.
Это не "дали возможность" эта фишка системы, они именно для этого такой мощный интерконнект делали. Не говори ерунды, 900 ГБ/с между любыми GPU в системе это много, считалкины как дети малые будут радоваться новой игрушке, её возможностям и удобству единой системы. Нет это не традиционный MPP суперкомп, не спорь.
-
Scoffer
Member
vmsolver
Це копійки. У мене тут якісь жалюгідні 4-нодові кластера на інтерконектах 4*50Гб/с крутяться, і періодами вусмерть утилізують мережу, не маючи при цьому ніяких відях на борту. А то 256 нод. З відеокартами. І шареною оперативою. Пхах. Завалиться і не встане.
Мінімум в 10 раз інтерконект підняти, і можна буде поговорити про шаринг пам'яті.
Відправлено через 17 хвилин 45 секунд:
960 ГБ/с тільки здається що багато, поки не почнеш ділити на кількість нод.
3,75ГБ/с=30Гб/с. Це навіть не топчик серед звичайних рядових серваків. І взагалі ні про що коли мова йдеться про доступ до оперативи. Там же не буде свіча зі стотерабітною сумарною ПС, інакше Хуанг про ньго гарантовано заявив би.
Відправлено через 12 хвилин 40 секунд:
Знайшов я, NVSwitch Third Generation Total aggregate bandwidth 7.2TB/s
Ну, непогано, непогано. Якщо припустити що доступ до пам'яті буде відбуватись не зовсім рандомно, то це 225 Гб/с на рило. Ну а якщо зовсім, то та ж тридцятка бо упреться не в свіч, а в нвлінк на ноді.
Але, як на мене, все одно малувастенько буде.
Це копійки. У мене тут якісь жалюгідні 4-нодові кластера на інтерконектах 4*50Гб/с крутяться, і періодами вусмерть утилізують мережу, не маючи при цьому ніяких відях на борту. А то 256 нод. З відеокартами. І шареною оперативою. Пхах. Завалиться і не встане.
Мінімум в 10 раз інтерконект підняти, і можна буде поговорити про шаринг пам'яті.
Відправлено через 17 хвилин 45 секунд:
960 ГБ/с тільки здається що багато, поки не почнеш ділити на кількість нод.
3,75ГБ/с=30Гб/с. Це навіть не топчик серед звичайних рядових серваків. І взагалі ні про що коли мова йдеться про доступ до оперативи. Там же не буде свіча зі стотерабітною сумарною ПС, інакше Хуанг про ньго гарантовано заявив би.
Відправлено через 12 хвилин 40 секунд:
Знайшов я, NVSwitch Third Generation Total aggregate bandwidth 7.2TB/s
Ну, непогано, непогано. Якщо припустити що доступ до пам'яті буде відбуватись не зовсім рандомно, то це 225 Гб/с на рило. Ну а якщо зовсім, то та ж тридцятка бо упреться не в свіч, а в нвлінк на ноді.
Але, як на мене, все одно малувастенько буде.
-
ronemun
Advanced Member
Scoffer
Ти відстав - 900 Гбайт/с (не біт) NVLink це швидкість всередині кожної ноди між gpu і процом. При цьому в gpu свої 96 ГБайт HBM, всі 6 чіпів по 16 Гбайт, кожен має майже 1 Тбайт/с, сумарно 5+ Тбайт/с, а в проца ще 512 ГБ на 320+ Гбайт/с, куди gpu може дані скинути. Звязок аж 900 Гбайт/с очевидно потрібен для спільної обробки і два різних пристрої працюють як одне ціле, там затримка на рівні кешу L3 або менше
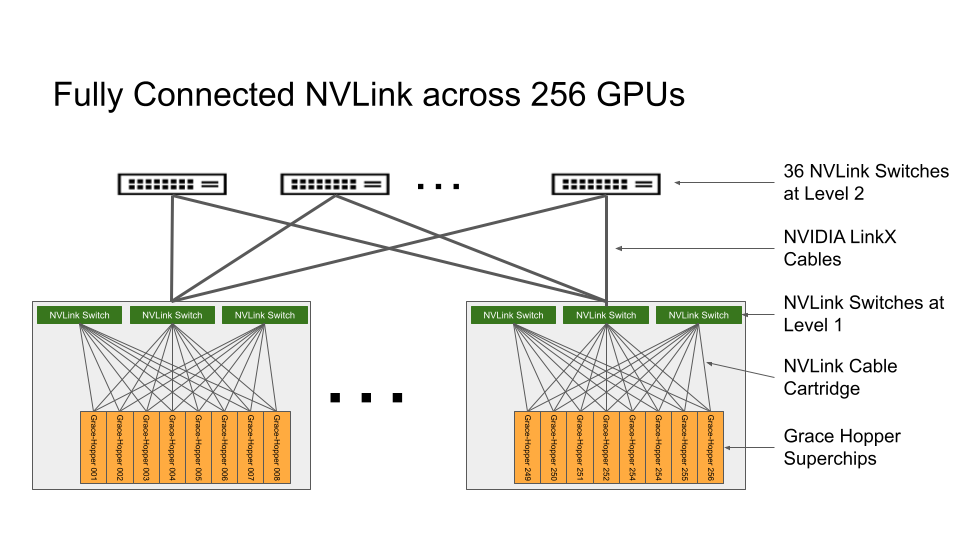
І все повязане спільним NVLink в зовнішній свіч, і так для кожної з 256 нод в стойки і ще між стойками суперзвязки 400+200+200 Гбіт/с= 100 Гбайт/с кожен лінк, всього 200+ км оптики. В нвідії вже звичайні свічі по 50+ Тбіт/с, тут 66 шт, а 96+32 NVlink свічі це взагалі монстри з кеш-когерент і доступом в кілька нс і т.п.
Загальна кількість тільки зовнішніх звязків там більше Петабайт/с
Ти відстав
І все повязане спільним NVLink в зовнішній свіч, і так для кожної з 256 нод в стойки і ще між стойками суперзвязки 400+200+200 Гбіт/с= 100 Гбайт/с кожен лінк, всього 200+ км оптики. В нвідії вже звичайні свічі по 50+ Тбіт/с, тут 66 шт, а 96+32 NVlink свічі це взагалі монстри з кеш-когерент і доступом в кілька нс і т.п.
Загальна кількість тільки зовнішніх звязків там більше Петабайт/с
Востаннє редагувалось 30.05.2023 02:10 користувачем ronemun, всього редагувалось 1 раз.
-
Scoffer
Member
ronemun
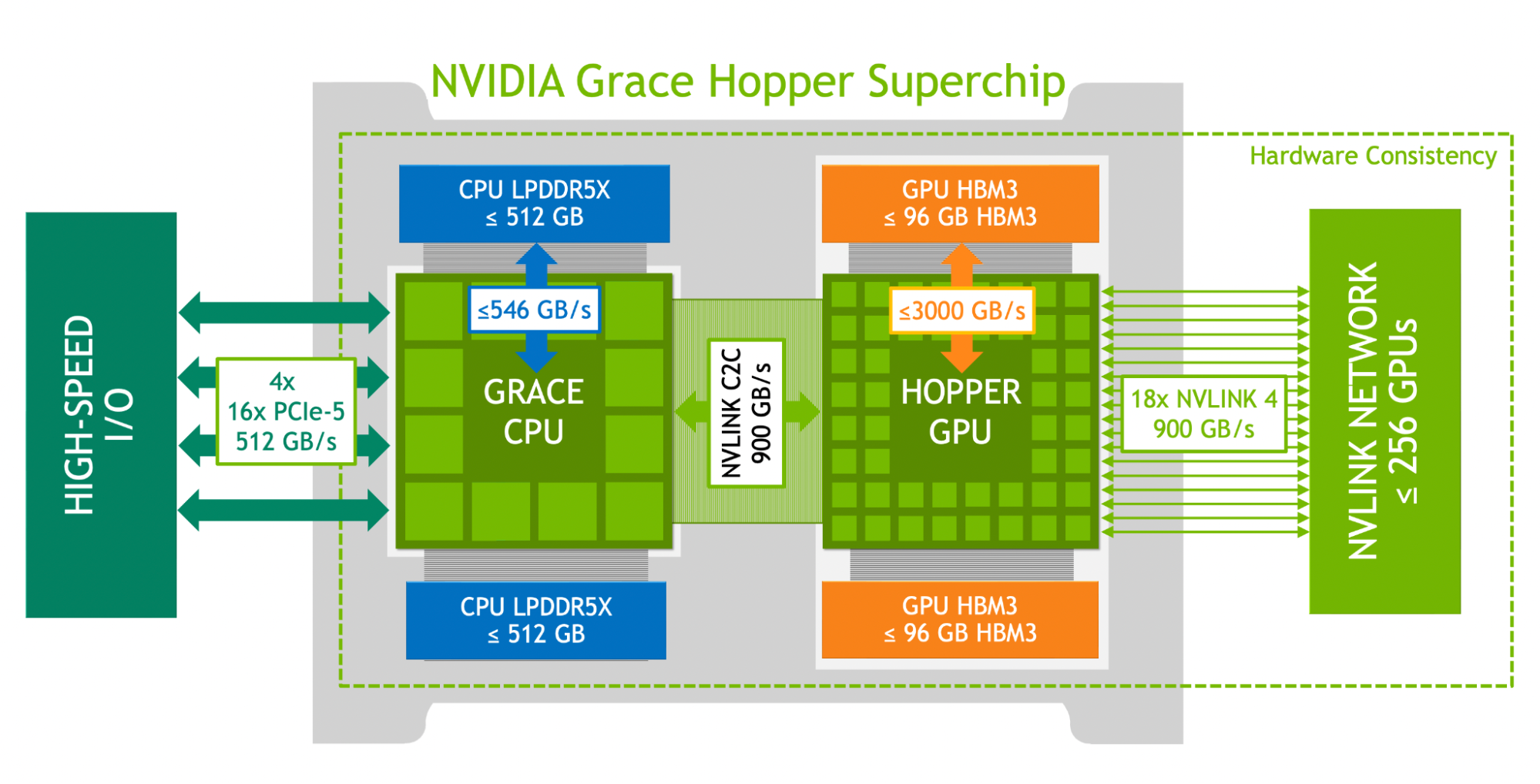
Біти з байтами у мене вказані вірно. Відеокарти пов'язані 960 ГБ/с нвлінком через два 7.2ТБ/с нвсвіча.
Відповідно швидкість доступу буде сильно залежати від того куди саме. Якщо це сусідній чіп з лінійним читанням/записом, то може бути і 960, якщо не дуже сусідній, то це вже 28,8ГБ/с, а якщо повний рандом, то 3,75ГБ/с. Все звісно при 100% утилізації мережі. Норм виделка швидкостей?
Як на MPP інтерконект більш ніж норм. Як на SMP це фігня фігнею. Куртка просто маркетингом займається. Наче ніде і не збрехав, але як дійде до реальних завдань, то буде не так радісно як на картинках. SMP не просто так ніхто не будує вже декілька десятиліть.
Біти з байтами у мене вказані вірно. Відеокарти пов'язані 960 ГБ/с нвлінком через два 7.2ТБ/с нвсвіча.
- спойлер
- спойлер
Відповідно швидкість доступу буде сильно залежати від того куди саме. Якщо це сусідній чіп з лінійним читанням/записом, то може бути і 960, якщо не дуже сусідній, то це вже 28,8ГБ/с, а якщо повний рандом, то 3,75ГБ/с. Все звісно при 100% утилізації мережі. Норм виделка швидкостей?
Як на MPP інтерконект більш ніж норм. Як на SMP це фігня фігнею. Куртка просто маркетингом займається. Наче ніде і не збрехав, але як дійде до реальних завдань, то буде не так радісно як на картинках. SMP не просто так ніхто не будує вже декілька десятиліть.
-
ronemun
Advanced Member
Сумарна швидкість NVlink назовні 900 Гбайт/с з кожної ноди, і вони розкидані на декілька свічів, і так з кожної ноди. Оскільки обчислення сильно розподілені вся швидкість сумується. Вони могли зробити все просто в один свіч, а свічі вже між собою зєднати, але ясно це збільшило б затримку бо було б багато переходів між свічами на кожне зєднання. А так як могли оптимізували, кращого і потужнішого навряд чи можливо придумати
SMP вже давно фікція, тут головне штучний інтелект, а йому потрібна гігатська швидкість між нодами з мінімальною затримкою, обробка йде послідовно, напевно, поетапно
SMP вже давно фікція, тут головне штучний інтелект, а йому потрібна гігатська швидкість між нодами з мінімальною затримкою, обробка йде послідовно, напевно, поетапно
Востаннє редагувалось 30.05.2023 02:24 користувачем ronemun, всього редагувалось 1 раз.
-
Scoffer
Member
ronemun
Ну ти ж слідкуй з чого спір почався. Якщо обчислення сильно розподілені, то у мене претензій взагалі ніяких немає. Самий звичайний традиційний суперкомп, котрих тисячі.
Але як vmsolver вірно підмітив, куртка росказав що воно улюлюпер моновідеокарта. І от на цьому пункті починають з'являтись питання що все не так просто. І чим більше її рахувати як моно, тим більше не просто буде.
Ну ти ж слідкуй з чого спір почався. Якщо обчислення сильно розподілені, то у мене претензій взагалі ніяких немає. Самий звичайний традиційний суперкомп, котрих тисячі.
Але як vmsolver вірно підмітив, куртка росказав що воно улюлюпер моновідеокарта. І от на цьому пункті починають з'являтись питання що все не так просто. І чим більше її рахувати як моно, тим більше не просто буде.
-
ronemun
Advanced Member
так відеокарта це і є зараз кластери, навіть всередині одного чіпа, з суперзвязками між ними. Так і тут точна копія, тільки маштабована. В чіпі планувальник розподіляє велику задачу на окремі кластери, ті вже своїми планувальниками на дрібніші і т.п.
Проци тут вже підчиняються загальному планувальнику, фактично частина відяхи, як і давно мало б бути, бо це дурдом на сучасних відяхах коли кожен кадр має проц зовні сказати як робити, і часто теж саме задавати відясі, коли її внутрішній конвеєр в тисячу раз сильніший лише тупі елементарні операції робить. Ну і масу операцій графіки/gpgpu краще робити гібридно, з процом паралельно - так і відяха краще використовується, і алгоритми в рази крутіші можна зробити
Фактично, основне правило обчислень - це дані для обробки мають знаходитись якомого ближче до ядер де вони потрібні для інших даних, щоб потрібно було менше передач даних. Вони тому і зліпили проц і відяху. АМД і Інтел теж так зробили. Інтел взагалі АІ в проц запхала, в кожне ядро - АІ генерує колосальну кількість даних і їх тре підготувати і фільтрувати - навіщо це кожен раз кудись передавати якщо можна тут же в ядрі це зробити. Краще кеші обрізати і т.п. - вони ж роботу не роблять, а на їх місце ядра великі з АІ і FPU
Відправлено через 32 хвилини 13 секунд:
Щодо звязків на рівні L2 мережі то крім прямого звязку через один свіч, можна використати інші ноди як посередник, всього 30 штук, вийде 1 прямий звязок через 1 свіч і 30 додаткових через свіч-нода-свіч. Це все одно сама коротша мережа з можливих для таких маштабних обчислень. І це тільки NVLink. А ще є 400 Гбіт/с дуплекс через проц
Проци тут вже підчиняються загальному планувальнику, фактично частина відяхи, як і давно мало б бути, бо це дурдом на сучасних відяхах коли кожен кадр має проц зовні сказати як робити, і часто теж саме задавати відясі, коли її внутрішній конвеєр в тисячу раз сильніший лише тупі елементарні операції робить. Ну і масу операцій графіки/gpgpu краще робити гібридно, з процом паралельно - так і відяха краще використовується, і алгоритми в рази крутіші можна зробити
Фактично, основне правило обчислень - це дані для обробки мають знаходитись якомого ближче до ядер де вони потрібні для інших даних, щоб потрібно було менше передач даних. Вони тому і зліпили проц і відяху. АМД і Інтел теж так зробили. Інтел взагалі АІ в проц запхала, в кожне ядро - АІ генерує колосальну кількість даних і їх тре підготувати і фільтрувати - навіщо це кожен раз кудись передавати якщо можна тут же в ядрі це зробити. Краще кеші обрізати і т.п. - вони ж роботу не роблять, а на їх місце ядра великі з АІ і FPU
Відправлено через 32 хвилини 13 секунд:
Щодо звязків на рівні L2 мережі то крім прямого звязку через один свіч, можна використати інші ноди як посередник, всього 30 штук, вийде 1 прямий звязок через 1 свіч і 30 додаткових через свіч-нода-свіч. Це все одно сама коротша мережа з можливих для таких маштабних обчислень. І це тільки NVLink. А ще є 400 Гбіт/с дуплекс через проц