
Та давайте вже FP150 петафлопс у форматі FP4
Новости
Последние статьи и обзоры
NVIDIA наживо показала суперчип Vera Rubin, який об’єднує два великих GPU і один CPU
-
Scoffer
Member

Пропоную обговорити NVIDIA наживо показала суперчип Vera Rubin, який об’єднує два великих GPU і один CPU

-
1234waltz
Member
>Ми вам покажемо Супер-Чіп
>Чіп
>Показують серверну материнську плату
Щось з опери, про називання дата-центрів генеруючих AIslop для тікток-хом'яків "Фабриками" в маркетингових матеріалах.
>Чіп
>Показують серверну материнську плату
Щось з опери, про називання дата-центрів генеруючих AIslop для тікток-хом'яків "Фабриками" в маркетингових матеріалах.
-
leks
Junior
Крузіс на максималках потягне?
-
nazar-pc
Member

Цікаво, в ARM екосистемі SMT не часто зустрічаєтьсяПроцесор Vera отримав 88 ядер, які обробляють 176 потоків
-
Scoffer
Member
Скоріше цікаво що зараз єдине відоме ядро з підтримкою SMT це Neoverse E1 бородатого 2017го року.nazar-pc: ↑ 29.10.2025 10:48Цікаво, в ARM екосистемі SMT не часто зустрічається
-
penetrator
Member
- Откуда: Amsterdam
И на премаркете NVDA уже 5+ триллионов 
-
Lucas55
Member

- Откуда: Сверхскопление Ланиакея Местная группа галактик Млечный Путь Солнечная система планета Земля
Мабуть це - народження Термінатора
-
gregory_amd
Member
- Откуда: Харьков
Почему нвидиа постоянно называют суперчипом материнку...
-
ronemun
Advanced Member
ТОму що це реально СУПЕРчіп, він максимально стиснутий, але на даний момент менше вже неможливо.gregory_amd: ↑ 29.10.2025 12:08 Почему нвидиа постоянно называют суперчипом материнку...
Є просто чіпи - зєднання мікрочіпів/кристалів в одну збірку, наприклад 8 кристалів dram/flash в один чіп.
Є великі чіпи і SOC - зєднання на одній підкладці чіпів і кристалів, наприклад проци АМД Epyc чи присколювачі з HBM.
А це суперчіп - зєднання великих чіпів/просто чіпів/кристалів в одну суперсистему.
Відміна від материнки в тому що зєднання такої швидкості що всє є одним цілим - має єдиний пул памяті, спільну адресацію, а шини звязку Терабайти/с. Розміри вийшли великі, а які ще можуть бути при таких компонентах.
в 28 році вийде версія Ultra де 1 чіп ШІ буде мати 4 кристали і 1 Тбайт памяті HBM
-
1234waltz
Member
Ніт. Це буквально распайка розсипухи. Немає там суперчіпсуперсистеми. GPU з процом по старому-доброму nvlink підключені, як і в рішеннях з змінними gpu. Системна пам'ять lpddr навіть по uma не зв'язана, системна ram окремо, hbm для gpu - окремл. Мережа окремо від процсора та gpu, як і на "класичних" системах. Просто блюфілд та спектрум, буквально в форматі їх дискретних плат на материнці розпаяні.ronemun: ↑ 29.10.2025 13:11 ТОму що це реально СУПЕРчіп, він максимально стиснутий, але на даний момент менше вже неможливо.
Відправлено через 4 хвилини 4 секунди:
Просто рішення, яке не дозволить клієнтам міняти та робити часткові апгрейди інфраструктури. Здох один чип після гарантії, викидуй. Треба cpu чи gpu з часом прокачати - викидуй та купуй нове.
В той самий час, для x86 серверів не рідкість, коли на середені життєвого циклу міняються gpu, пам'ять тп речі. Боже, як же Leather man гріє гоїв під час ai істерії.
-
vmsolver
Member

А что такое материнская плата?gregory_amd: ↑ 29.10.2025 12:08 Почему нвидиа постоянно называют суперчипом материнку...
То, что они размером в маленькую МП не означает, что это не чип, хотя лучше назвать SoP (System on Package), который формально тоже чип, а так как он большой, назвали суперчип.
-
max1996
Member
А в kirin?Scoffer: ↑ 29.10.2025 10:56Скоріше цікаво що зараз єдине відоме ядро з підтримкою SMT це Neoverse E1 бородатого 2017го року.nazar-pc: ↑ 29.10.2025 10:48Цікаво, в ARM екосистемі SMT не часто зустрічається
-
ronemun
Advanced Member
1234waltz
ви явно не в курсі, а таке пишете - lpddr, підключена до проца, там якраз в тому ж адресному просторі що і HBM підключена до AI-чіпів.
Навіть більше, там загальний адресний простір для всіх суперчіпів в стійці на 144 кристали AI - для того NVlink і є.
Сеаме тому воно називається NVL144 - там все спільне і має максимально короткий доступ точка-точка всі-до-всіх
на одну стійку там багато кілометрів кабелів тому що кожен такий суперчіп приєднаний до всіх 35 інших напряму, для максимального використання памяті.
ви явно не в курсі, а таке пишете - lpddr, підключена до проца, там якраз в тому ж адресному просторі що і HBM підключена до AI-чіпів.
Навіть більше, там загальний адресний простір для всіх суперчіпів в стійці на 144 кристали AI - для того NVlink і є.
Сеаме тому воно називається NVL144 - там все спільне і має максимально короткий доступ точка-точка всі-до-всіх
на одну стійку там багато кілометрів кабелів тому що кожен такий суперчіп приєднаний до всіх 35 інших напряму, для максимального використання памяті.
-
oleg5d75
Member
- Откуда: Суми, Україна
Буду брать, не знаю поки навіщо але виглядає красиво і блищить ")
-
Scoffer
Member
Який саме? їх купа найменуваньmax1996: ↑ 29.10.2025 13:48А в kirin?
-
ronemun
Advanced Member
забудьте про звичайні сервери. Це ШІ - це ріст в геометричній прогресії - в 26 році VR NVL72 буде в 3,3 рази сильніше за зарашній GB NVL144, а в 27му VR ultra NVL576 - ще в 4 рази. Тут все хмара прямо від Нвідії - там тільки кабелів в одній стійці десятки кілометрів, свічів 10ки, а споживання вже зараз 120 кВт, в 26му - 400, а в 27 - 1 МВт на стійку. ТАм все вода, навіть подача живлення 800 Вольт буде мати своє водяне охолодження. Все це пропрієтарне, настільки нове що такого ще нігде ніколи не було, його зможуть обслуговувати лише спеціальні навчені команди, сертифіковані для цього на основі роботи попередніх проектів. Там просто захмарні технології.1234waltz: ↑ 29.10.2025 13:28 Просто рішення, яке не дозволить клієнтам міняти та робити часткові апгрейди інфраструктури. Здох один чип після гарантії, викидуй. Треба cpu чи gpu з часом прокачати - викидуй та купуй нове.
В той самий час, для x86 серверів не рідкість, коли на середені життєвого циклу міняються gpu, пам'ять тп речі. Боже, як же Leather man гріє гоїв під час ai істерії.
Ось що пише на сайті :
"Шафа GB300 NVL72 являє собою фундаментальний перехід від "серверів у стійках" до "центрів обробки даних у шафах". Фізика невблаганна: 120 кВт обчислювальної потужності вимагають точності в кожному підключенні живлення, контурі охолодження та термінації оптоволокна"
-
1234waltz
Member
ronemun: ↑ 29.10.2025 13:49 ви явно не в курсі, а таке пишете - lpddr, підключена до проца, там якраз в тому ж адресному просторі що і HBM підключена до AI-чіпів.
Навіть більше, там загальний адресний простір для всіх суперчіпів в стійці на 144 кристали AI - для того NVlink і є.
- спойлер
-
Все спільне, але варитись у власному котлі вміє тільки GPU зі своєю власною пам'ятью. Коли все влазить в пам'ять одного GPU - все працює просто фантастично легко та швидко. А коли треба вийти за пам'ять одного GPU, починаються більш складні речі, в тому числі і зі сторони софта. Слайди з технічних гайдів Хуаніти, якщо шо.
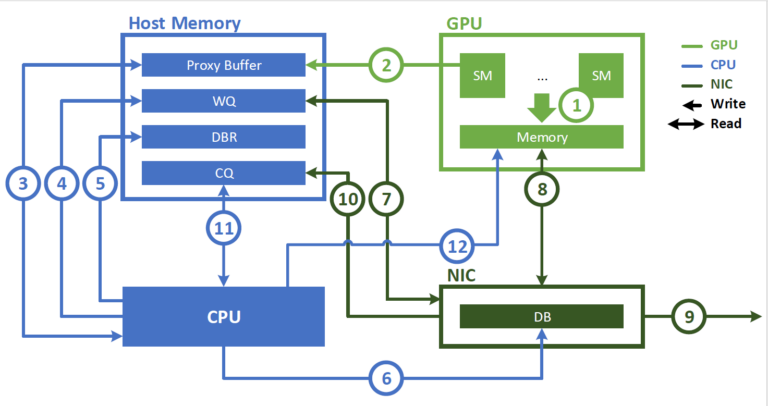

А коли треба вийти за пам'ять одного GPU, починаються більш складні речі. За межами однієї стійки, ще складніші. В тому числі і на стороні софта. На semianalytics розбирали окремо пару Rubin CPX (а не 144 відразу) і в них виникли логічні проблеми з усім цим перегоном даних.
For instance, DeepSeek V3 when running on the NVFP4 number format will require 335GB of memory capacity to load all the model weights – this exceeds the 128GB of memory capacity of a single CPX chip. This can be overcome by using pipeline parallelism (‘PP’), where multiple layers of a model are split across different GPUs. In PP, each GPU processes tokens sequentially and will pass activations down the pipeline.
The disadvantage of PP is that the tokens are passed sequentially across many GPUs, incurring latency from inter-stage communications. The important implication is that PP will tend to deliver higher token throughput per GPU than Expert Parallelism (EP), but the tradeoff is that PP suffers from a higher time to first token (TTFT) than EP. PP has higher tok/s/gpu throughput because EP has high communications overhead as it involves all-to-all collective operations vs a simple send and receive operation in the case of PP.
we show that prefill for DeepSeek using a parallelism scheme of PP8 or PP4 results in a message size per token of 7kB. If we were to fully saturate the PCIe Gen6 x16 lanes of I/O with messages, this means we could at most transmit (and therefore process) 18.3M tokens per second. This is the communications bound.
Turning to the compute bound scenario, we see that prefill FLOP per token is 0.074 TFLOP. So, if we divide the Rubin CPX’s dense FP4 throughput of 19,800 PFLOPS by 0.074 TFLOP, we arrive a maximum token throughput of 267.6k tokens/second.
This is far below the communications bound and vastly under saturates even a fairly vanilla PCIe Gen6 I/O let alone NVLink which delivers over 14x the bandwidth of 16 lanes of PCIe Gen6.
We estimate that the total NVLink Scale-up cost to the end system owner (inclusive of NVSwitches and Backplane) stands at around ~$8k per GPU – which is just over 10% of the all-in cluster cost per GPU. This is the other dimension along which Rubin CPX delivers considerable savings to the end user.
However, attempting to use Expert Parallelism with lower speed networking connectivity will lead to latency issues and bottlenecks. Communications need scale with respect to the product of top_k times number of layers. DeepSeek V3 has a top_k of 8 and has 61 layers, so a back of the envelope calculation would indicate that using EP over PP would increase communications requirements by ~488x.
От і виходить, в маркетингових матеріалах суперчип, спільний доступ і тп. В реальності під капотом це дуже складна топологія, як і на класичних севрерах з дискреткою, з NVLink, InfiniBand та ethernet з можливістю ганяти дані в різних конфігураціях.
-
ronemun
Advanced Member
1234waltz
так і в АМД в одному ж проці ніби весь кеш L3 спільний, а по суті є локальний кеш L3, і є сусідній чіплет до якого затримка як в оперативну память. Але ж все одно це один Великий чіп на одній підкладці і АМД пише про 256 МБ кешу на 8 чіплетів по 32МБ в кожному.
ТАк само і тут.
Якщо чесно зараз дійсно немає сенсу у всезагальному кристалі/підкладці - все настільки величезне, ядер cpu/AI/щейдерів, що навіть один кристал всередині розбитий на багато підгруп зі своїми кешами/контролеарми памяті/внутрішніми шинами, навіть кільцевішини вже давно загнулись, а в Інтел навіть меш вже має 80нс затримки, а між кристалами всерелині чіпа ще +30/40нс. З другої сторони дуууже сильно виросла швидкість зовнішних шин, особливо між чіпами близько - NVLink це терабайти/с на один чіп, скоро буде 10+. Добавте чіпи-свічі на 125 Тбайт/с з підтримкою NVLink і інших протоколів синхроного кешу. Тож в Нвідії тепер це все одне єдине, там AI чіп напряму пише/читає в будь-який інший через +1, максимум 2 хаби, з додатковою затримклю +300/600нс, в них всі кеші/дані/адреми і шляхи спільні.
А далі піде 3д корпусування з десятками кристалів з ядрами CPU/AI/шейдери на одній суперпідкладці, як Інтел готує для Xeon, а АМД вже має в MI300/350. Там кожен кристал буде як Ryzen 9800x3d чіплет з ядрами на кристалі з кешом, швидкість 3 Тбайт/с на кожен кристал, а затримка 1-2 нс. А тепер уявіть цілі матриці таких кристалів, в декілька поверхів.
так і в АМД в одному ж проці ніби весь кеш L3 спільний, а по суті є локальний кеш L3, і є сусідній чіплет до якого затримка як в оперативну память. Але ж все одно це один Великий чіп на одній підкладці і АМД пише про 256 МБ кешу на 8 чіплетів по 32МБ в кожному.
ТАк само і тут.
Якщо чесно зараз дійсно немає сенсу у всезагальному кристалі/підкладці - все настільки величезне, ядер cpu/AI/щейдерів, що навіть один кристал всередині розбитий на багато підгруп зі своїми кешами/контролеарми памяті/внутрішніми шинами, навіть кільцевішини вже давно загнулись, а в Інтел навіть меш вже має 80нс затримки, а між кристалами всерелині чіпа ще +30/40нс. З другої сторони дуууже сильно виросла швидкість зовнішних шин, особливо між чіпами близько - NVLink це терабайти/с на один чіп, скоро буде 10+. Добавте чіпи-свічі на 125 Тбайт/с з підтримкою NVLink і інших протоколів синхроного кешу. Тож в Нвідії тепер це все одне єдине, там AI чіп напряму пише/читає в будь-який інший через +1, максимум 2 хаби, з додатковою затримклю +300/600нс, в них всі кеші/дані/адреми і шляхи спільні.
А далі піде 3д корпусування з десятками кристалів з ядрами CPU/AI/шейдери на одній суперпідкладці, як Інтел готує для Xeon, а АМД вже має в MI300/350. Там кожен кристал буде як Ryzen 9800x3d чіплет з ядрами на кристалі з кешом, швидкість 3 Тбайт/с на кожен кристал, а затримка 1-2 нс. А тепер уявіть цілі матриці таких кристалів, в декілька поверхів.
-
1234waltz
Member
Оце буде цікаво, але страшно уявити майбутні ціни та те, як будуть вирішувати проблеми з відводом тепла й споживанням.ronemun: ↑ 29.10.2025 15:20 А далі піде 3д корпусування з десятками кристалів з ядрами CPU/AI/шейдери на одній суперпідкладці, як Інтел готує для Xeon, а АМД вже має в MI300/350. Там кожен кристал буде як Ryzen 9800x3d чіплет з ядрами на кристалі з кешом, швидкість 3 Тбайт/с на кожен кристал, а затримка 1-2 нс. А тепер уявіть цілі матриці таких кристалів, в декілька поверхів.