
catdoom
я обсуждаю конкретные теоретические материалы, там текста много, а смысла конечно мало, больше смысла фанбойствовать и гнать отсебятину и домыслы, и про какие 1-2 фпс ты говоришь? 3080 и 3090 объективно имеют больше мощи, и вот как раз при включении DLSS и лучей это и видно и там далеко не 1-2 фпс. Поглядим какое мыльцо предложит АМД без тензоров.
Последние статьи и обзоры
Новости
AMD FidelityFX Super Resolution поддерживается видеокартами Radeon и GeForce
-
kyon
Member
-
Haulr
Member
А от и "нефонат" и показал свое лицоkyon: ↑ 02.06.2021 10:58 catdoom
я обсуждаю конкретные теоретические материалы, там текста много, а смысла конечно мало, больше смысла фанбойствовать и гнать отсебятину и домыслы, и про какие 1-2 фпс ты говоришь? 3080 и 3090 объективно имеют больше мощи, и вот как раз при включении DLSS и лучей это и видно и там далеко не 1-2 фпс. Поглядим какое мыльцо предложит АМД без тензоров.
И да, привыкай к фиделити,т.к. длсс повторит судьбу г-синка
-
kyon
Member
Haulr
- спойлер
- 3090 > 6900XT
идет вровень и кое где отстает но там сцены совсем простенькие, я бы хотел видеть открытые пространства с большим кол-вом деталей
3090>6900XT
3090>6900XT
3090>6900XT
это и есть типичное фанбойство, FSR еще и в помине нет и "билив" как раз у тебя что FSR будет лучше, не основанное ни на чем мнение, еще раз, я опираюсь на конкретную аналитику по 2 картам.да, привыкай к фиделити,т.к. длсс повторит судьбу г-синка
Последний раз редактировалось kyon 02.06.2021 11:36, всего редактировалось 1 раз.
-
Haulr
Member
Ох уж эти тесты не тесты... Чел, если твои ФП32 так роляли, то 6900хт была бы слабее 3080, не то что 3090, в любом сценарии, но по итогу в половине игр или на ровне или быстрее в 4к, а в 1440р и вовсе смеется. Так где твои хваленные ФП32 и почему они не дают буст?kyon: ↑ 02.06.2021 11:16 Haulr
Более-менее больше у 6900ХТ только в Ларке, причем там в каком-то очке она сидит, да и в остальных играх в основном сцены простые, а то и вообще кат-сцены, я хотел бы видеть открытый мир с большим кол-вом деталей. Тут такое впечаление что тесты так подобраны чтобы вытянуть 6900ХТ, ведь она скейлится в 4к хуже же.
- спойлер
- 3090 > 6900XT
идет вровень и кое где отстает но там сцены совсем простенькие, я бы хотел видеть открытые пространства с большим кол-вом деталей
3090>6900XT
3090>6900XT
3090>6900XT
это и есть типичное фанбойствода, привыкай к фиделити,т.к. длсс повторит судьбу г-синка
Или ты это называешь победой? Тоже не оптимизировано под нвидию? Просто шакальный фреймрейт из пик на 3090. Сцена просто легкая видимо
- Вложения
-
-
-
-
kyon
Member
Haulr
А теперь тесты там где Нвидиа оптимизирована и там где архитектура Ампер сильна, в 1440р как ты любишь, и в самом высоком качестве. 6900 ХТ зашакалила Тензоры и РТ и показывает шакальный фреймрейт.
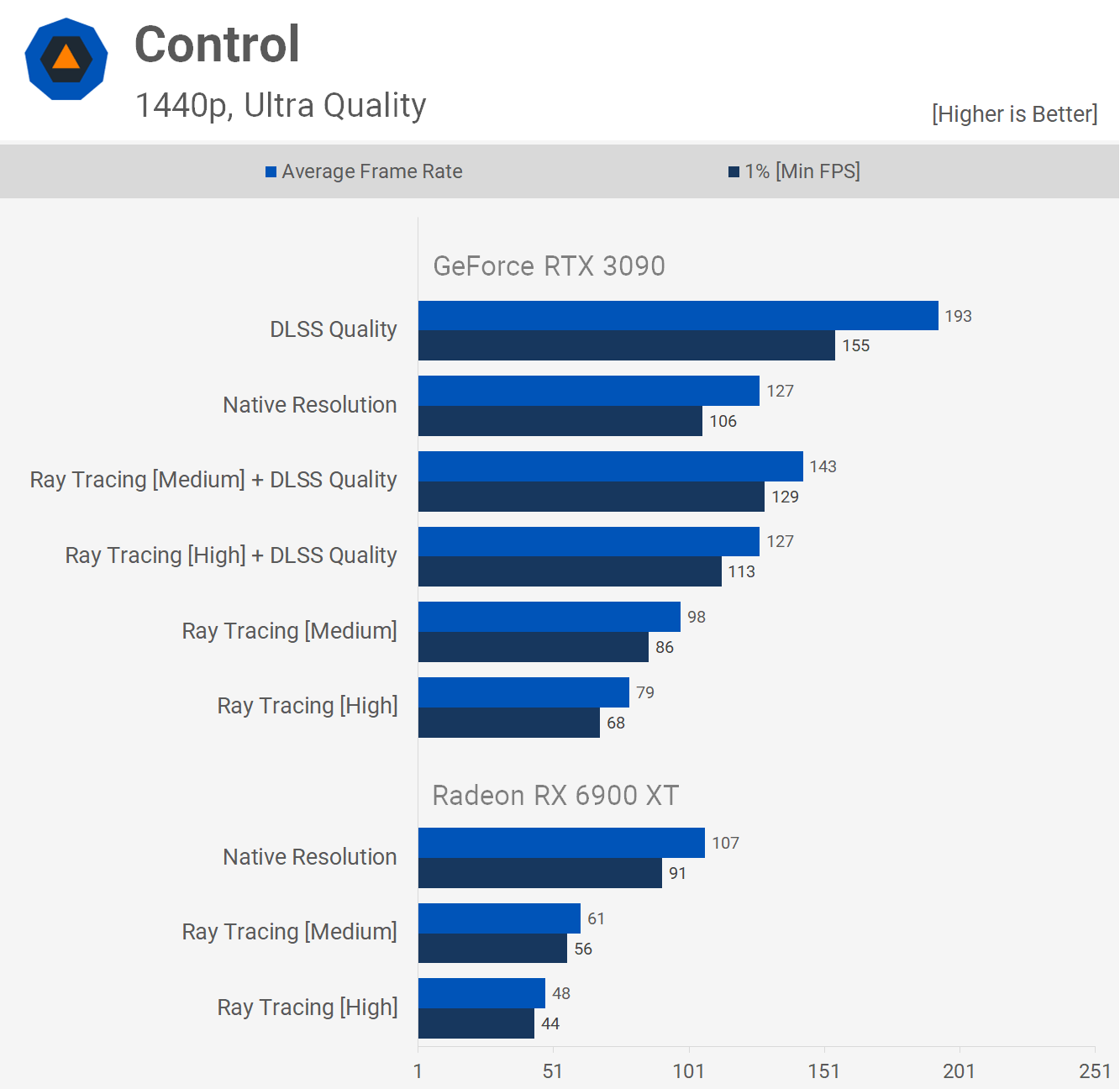
А вот и Ларка
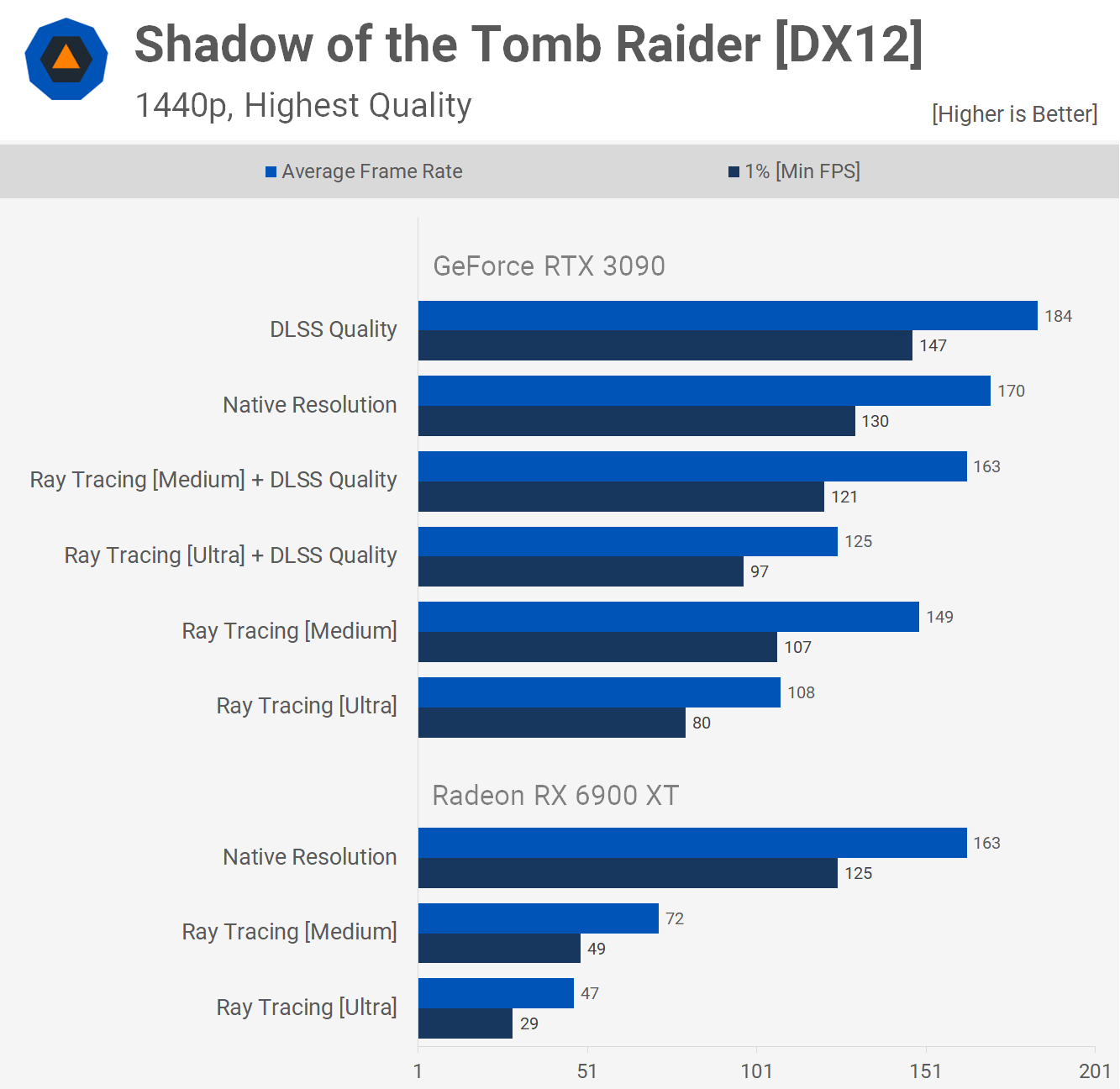
Конечно у 3090 шакальный фреймрейт, а у 6900ХТ не еще более шакальный. Вот это типичное фанбойство, обосрать конкурента, и самому обосраться
А теперь тесты там где Нвидиа оптимизирована и там где архитектура Ампер сильна, в 1440р как ты любишь, и в самом высоком качестве. 6900 ХТ зашакалила Тензоры и РТ и показывает шакальный фреймрейт.
А вот и Ларка
Конечно у 3090 шакальный фреймрейт, а у 6900ХТ не еще более шакальный. Вот это типичное фанбойство, обосрать конкурента, и самому обосраться
-
1nsane
Member
- Откуда: Ларнака, Кипр
Дополню Ваш ответ небольшим эксурсом в нейросети и как они работают. Вы в конце поймете, для чего.catdoom: ↑ 01.06.2021 20:08"не требует предварительного обучения нейросети" нвидиафилы уже всё перекрутили в верх дном и выплёвывают носом.NeeDforKill: ↑ 01.06.2021 18:23Нету никакого там DirectML и никакие нейронки не участвуют в этом.
1. Сначала создается модель нейросети с ее уровнями, узлами, функциями узлов, и т. д. Она компилируется в готовую нейросеть, но пустую.
2. Дальше подготавливаются данные, которые скармливаются нейросети, и нейросеть таким образом тренируется (=обучается).
2.1 Этот процесс повторяется с варьированием вводных данных, а также параметров нейросети, пока ты не получишь желаемый результат.
3. Когда желаемый результат получен, ты можешь сохранить готовую модель натренированной нейросети для использования!
Под "не требует предварительного обучения нейросети" АМД имеет в виду, что технология представляет собой отдельно натренированную под конкретную игру модель нейросети, которую тебе не нужно тренировать самому. Все, что требуется - скамливать ей воодные данные и получать результат. Технология закидывает тебя на 3 пункт из описанных выше, тогда как первые два были проблемами разраба или самой АМД. Потому и "не требует предварительного обучения". Но сама нейросеть есть. Просто натренированная и уже готовая к использованию.
-
zoog
Member
На разных движках, моделях, текстурах и эффектах - одна модель?1nsane: ↑ 02.06.2021 15:14Просто натренированная и уже готовая к использованию.
-
Zzz_rob
Member
Ты хоть эти 50 проектов сыграл/открывал?alexxusss: ↑ 01.06.2021 13:14 Цікаво, наскільки швидко будуть адаптувати? В UE5 є схожа фіча на рівні рушія, називається TSR. Вона Platform-Agnostic. Зараз з DLSS 2 є десь 50+ проектів, але це ж все одно мало.
-
pornbuild
Member
- Откуда: Улан-Удэ
Зачем вообще придумали все эти сложности? На транзисторный бюджет которые отводятся для рейтрейсинга/длсс могли бы добавить еще больше обычных шейдеров - и прирост в нативе был бы еще более запредельным. Глядишь, а там и до заветных "4к/60фпс ультра" дошли бы.1nsane: ↑ 02.06.2021 15:14Дополню Ваш ответ небольшим эксурсом в нейросети и как они работают. Вы в конце поймете, для чего.catdoom: ↑ 01.06.2021 20:08
"не требует предварительного обучения нейросети" нвидиафилы уже всё перекрутили в верх дном и выплёвывают носом.
1. Сначала создается модель нейросети с ее уровнями, узлами, функциями узлов, и т. д. Она компилируется в готовую нейросеть, но пустую.
2. Дальше подготавливаются данные, которые скармливаются нейросети, и нейросеть таким образом тренируется (=обучается).
2.1 Этот процесс повторяется с варьированием вводных данных, а также параметров нейросети, пока ты не получишь желаемый результат.
3. Когда желаемый результат получен, ты можешь сохранить готовую модель натренированной нейросети для использования!
Под "не требует предварительного обучения нейросети" АМД имеет в виду, что технология представляет собой отдельно натренированную под конкретную игру модель нейросети, которую тебе не нужно тренировать самому. Все, что требуется - скамливать ей воодные данные и получать результат. Технология закидывает тебя на 3 пункт из описанных выше, тогда как первые два были проблемами разраба или самой АМД. Потому и "не требует предварительного обучения". Но сама нейросеть есть. Просто натренированная и уже готовая к использованию.
-
TJ-ua
Member

- Откуда: Запоріжжя
будет смешно когда внезапно "фирменная технология Nvidia DLSS" станет доступна на видеокартах прошлого поколения 

-
1nsane
Member
- Откуда: Ларнака, Кипр
Не факт. Скорее всего, модель под каждый тайтл чем-то будет отличаться - кол-вом узлов в уровнях и функицей активации.zoog: ↑ 03.06.2021 03:19На разных движках, моделях, текстурах и эффектах - одна модель?1nsane: ↑ 02.06.2021 15:14Просто натренированная и уже готовая к использованию.
Ну и да, конечно, с каждой моделью будет идти свой пакет натренированных данных (веса векторов между узлами).
Я думаю, причин там много, и без подробностей мы далеки от каких-то существенных выводов)pornbuild: ↑ 03.06.2021 09:11 Зачем вообще придумали все эти сложности? На транзисторный бюджет которые отводятся для рейтрейсинга/длсс могли бы добавить еще больше обычных шейдеров - и прирост в нативе был бы еще более запредельным. Глядишь, а там и до заветных "4к/60фпс ультра" дошли бы.
И Вы недооцениваете скорость нейросетей. Это тренировать нейросеть на данных очень долго и ресурсозатратно. А вот получать результат от натренированной нейросети - потрясающе быстро. Для вычислительно техники это сродни простейшей математической операции. Может, поэтому лидерам индустрии и кажется, что получить апскейл от выдачи нейросети по ресурсам выгоднее, чем рендерить еще больше пикселей.
Ну и да, тензоры нвидии - скам. Спойлер: у них у самих же есть набор для разработчиков cudnn, который позволяет юзать куда-ядра в нейросетях как... тензоры)) (они же узлы, они же нейроны)
Так что их тензорные ядра - скорее всего просто урезанные куда, которые могут вычислять только список функций активации узлов (там тангенциальная функция в подавляющем большинстве и ее производные).
-
zoog
Member
1nsane: ↑ 03.06.2021 13:26Не факт. Скорее всего, модель под каждый тайтл чем-то будет отличаться - кол-вом узлов в уровнях и функицей активации.
Ну и да, конечно, с каждой моделью будет идти свой пакет натренированных данных (веса векторов между узлами)
Если бы модели кормились битмапами - в теории возможно. Но тогда всякие ДЛСС/СС можно было бы реализовывать как обычный шнйдер, просто вставив его в конвеер. По-моему, там глубоко взаимодействие с движком - сеть знает, что такое объекты, их границы (то, для чего в основном суперсэмплинг и нужен),где текстуры и где спрайты-эффекты.
-
1nsane
Member
- Откуда: Ларнака, Кипр
Согласен, это бы объяснило очень многое. Технически это может быть CNN, обученная на текстурках, т. к. отслеживать объекты в рилтайме - настолько же затратно, как и сам суперсемплинг. Я бы склонился к тому, что это модель, обученная с использованием внутренних фалов игры, и объекты детектятся средствами самой нн, а не движок передает ей данные - уж слишком большие потери мощности были бы.zoog: ↑ 03.06.2021 14:121nsane: ↑ 03.06.2021 13:26Не факт. Скорее всего, модель под каждый тайтл чем-то будет отличаться - кол-вом узлов в уровнях и функицей активации.
Ну и да, конечно, с каждой моделью будет идти свой пакет натренированных данных (веса векторов между узлами)
Если бы модели кормились битмапами - в теории возможно. Но тогда всякие ДЛСС/СС можно было бы реализовывать как обычный шнйдер, просто вставив его в конвеер. По-моему, там глубоко взаимодействие с движком - сеть знает, что такое объекты, их границы (то, для чего в основном суперсэмплинг и нужен),где текстуры и где спрайты-эффекты.
-
zoog
Member
Движку передать данные о десятке-другом-ну-пусть-сотне объектов трудно? Тем более внутри своего же процесса.
-
1nsane
Member
- Откуда: Ларнака, Кипр
Я думаю, дело не в затратах на "движок передает", а на затраты "нн обрабатывает переданное ей". Потому что это будет вмешательством в работу сети, которое влияет на ее выдачу. Вряд ли объект и его координаты - вводные данные для сети.zoog: ↑ 03.06.2021 14:40 Движку передать данные о десятке-другом-ну-пусть-сотне объектов трудно? Тем более внутри своего же процесса.
Хотя... кто знает. Технически можно и такое устроить. Запустить нейросеть и получить выдачу - предельно легко, дело пяти минут. А вот подобрать вводные данные правильно, чтобы еще и получить хорошую выдачу - совсем другое.