Scoffer:Anakha
Я вже мабуть сто раз розказував, але розкажу ще раз.
Не можна адміністративно, політично. Ти ніколи в житті не домовишся з різними департаментами чи ще краще юр особами однієї здорової контори щоб вони всілись на один сервак. Ти навіть не домовишся з одним і тим же департаментом під різні проекти тому, що це різні бюджети.
Тому один проект = мінімум один сервак.
Відправлено через 2 хвилини 56 секунди:
А є ще товариші з інформаційнох безпеки, котрі періодами задвигають зовсім цікаві правила що хоч стій хоч падай
Да ладно. Часто внутренние "заказчики" даже не подозревают где их сервера развернуты. В крупных компаниях давно все на виртуалках. Кроме некоторых задач, под которые физику выделяют.
очевидно, більш простіше було б кристали розміщати з 2 сторін однієї підкладки, як в оперативі. І радіатор надівати легше, і розмір сокета стає мінімальним, а головне - відстань між чіпами зменшується на порядки, і кількість доріжок у 2 рази, а отже і складність сітки і довжина шляхів обходу, втрати-розсіювання і взаємонаведення.
Теоретично так можна приєднувати кристалу кешу напряму до чіплетів, або зєднувати декілька чіпів через один спільний з протилежної сторони
Отправлено спустя 48 минут 8 секунд:
очевидно, вже пора щось робити з інтерфейсом DRAM - 5-10 Гбіт/с на контакт в DDR5 проти 32-64 в PCIe v5-6, при вже сотнях Терабіт/с на оптиці.
300 контактів заради 40-80 Гбайт/с на канал проти 65 контактів і 100 Гбайт/с (сумарно) в Нвідії/IBM
Коли кожен чіп з 8-16 кристалів памяті вже значно складніший і технологічніший ніж сам проц/чіплет - очевидно простіше контролер памяті перенести в саму память (чіп чи планку), і кожен виробник DRAM буде сам собі свій контролер розробляти
quazar
зовнішня поверхня доступу до кристалів залишається та ж сама, то яким чином зменшиться тепловідвід? тепловим трубкам однаково куди підводити - до однієї площини чи до двох. Все одно в будь-якому кулері декілька трубок
quazar:ronemun
Так, вроде, речь была о размещении кристаллов с двух сторон от подкладки. Как в таком случае организовать теплоотвод?
як в оперативі - планку (підкладку) в сокет-слот, вертикально-перпендикулярно до материнки, чи під кутом як в sodimm. Головне щоб було місце для підведення сплющеної теплової трубки прямо до чіпів чи що їх накриватиме
Scoffer
очевидно, що той же контролер і його інтерфейс є або в проці, або біля оперативи (LRDIMM, додаткові чіпи для Xeon E7). Тобто кремній все одно тратиться, але в проці він значно дорожчий через велику ціну одиниці площі великого кристалу. Контролер памяті є у будь-якому cpu чи gpu (і SSD-контролері і т.п), починаючи від 5 дол - в телефонах, відяхах, консолях, той же RasberiPi Zero. Це давно стандартний елемент, навіть розробляти непотрібно -він прямо в базі будь-якого виробника чіпів. Підключаєш його через будь-який інтерфейс і все. А зараз транспорт для всіх однаковий на основі сукупності диф. пар - USB, PCIe, IF, HT, NVLink, GENz, HDMI-Displayport і т.д - лише протокол кожен під себе гребе - хоча CXL і це вже вирішив, навіть когерентність кешу вже стандарт.
Але навіть по розміру IF-контролера і його інтрефейсу в АМД видно наскільки економніше і простіше підключатись через швидку шину. І в неї ще значно повільніший інтерфейс ніж у NVIDIA, яка теж через 8 двохсторонніх зєднань одним кристалом всього в 3 млрд. транзисторів 8 суперпотужних відеокарт зєднує, а не просто 8 ядер чіплети. Але при окремих контролерах памяті в проці тратиться місце лише для контролерів шин, через які можна підєднати будь-що: відяхи, SSD, FPGA, DRAM, і навіть інші хаби чи перетворювачі на PCIe, Ethernet/Infiniband, ефективніше розподіляючи ті шини між ними. А якщо в тебе в проці 12 контролерів памяті, а ти використовуєш лише 4 чи 6, то що робитимеш з вільними - за що ти платиш? Часто навіть на материнках не передбачається місце під таку кількість слотів-каналів
ronemun
Це має сенс лише в дуже жирних серваках на багато терабайт оперативи сумарно. Коли фізично неможливо оточити процесор необхідною кількістю стандартних модулів DIMM.
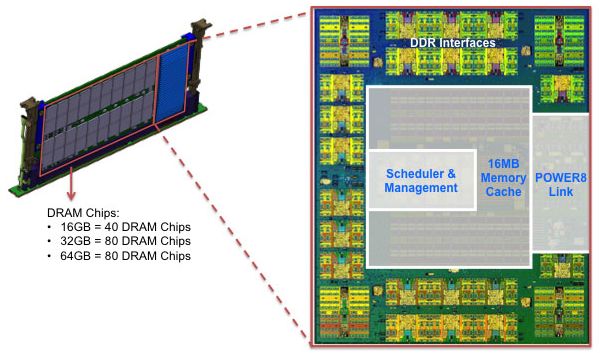
Чіп центавр з картинки вище, по пам'яті, має на борту десь 4 мільярди транзисторів. А аналогічний по функціоналу SC chip з IBM z14 всі 10 лярдів. Дуже багато місця займає кеш. Без кешу будуть непристойно великі середні затримки.
І в будь-якому випадку це не про дешевше. Це костиль щось хоч якось працювало на дуже потужних серверах.
і навіщо цей чіп, де не відомо на що потрачено 4 млрд. транзисторів на 2 канали паміті + 50 ГБ/с шину (сумарно в 2 сторони) , коли АМД має 8 каналів + 128 PCIe4 (512 ГБ/с) + 8 двох сторонніх IF (800 ГБ/с) + массу USB 3/ SATA3 контролерів + суперпотужний інтелектуальний хаб з кешами всередині і т.п з 9 млрд. трн. (ну чи звичаних процах в 4 рази меньше всього).
Я ж маю на увазі що все одно контролер памяті де - в проці чи назовні - той самий кремній іде на контролер, інтерфейс, і трохи кешу. Але в проці це значно дорожче, тому що ціна площі росте зі збільшенням кристалу, а окремо і дешевше, і значно меньше контактів для проца і для розведення доріжок на платі. А також ті шини можна просто кабельками розводити - як в Інтел напряму з проца/чіпсета. А головне що всі ті шини можна ефективно розподілити між корисними для себе пристроями, а не тільки для памяті. Сама шина типу NVlink взагалі незначно займає- в Нвдіії чіп на 2,7 млрд. трн. має 18 портів по 16 ліній (диф. пар) кожен, + декілька ліній PCIe для управління, ну і само собою матрицю комутації і кеші і т.п. Кожен порт забезпечує 50 ГБ/с в обидві сторони в сумі. 8 відях по 2 порти = 16 портів, ще 2 в запасі
Востаннє редагувалось 01.03.2021 23:57 користувачем ronemun, всього редагувалось 1 раз.
ronemun
Повторюсь, не виходить нічого путнього якщо не оснастити віддалений контролер оперативи значним кешем L4. Значний кеш L4 це дорого. В IBM, я думаю, шарять що роблять, інакше не вдорожчали б собівартість і без того не дешевого рішення.
Scoffer
дивно, ти мав би знати що в Інтел всі проци E7 мають зовнішній контролер - лінійка v2 і v3 три лінії по 2 канали, новіші - 4 лінії. І чомусь без всяких кешів L4, лише незначний кеш, як і в планках LR. Нічого дивного - DRAM і так занадто великі затримки має, а зарашні шини не порівняння з тим нещастям що колись було - 10 ГБіт/с на лінію - зараз вже 50 Гбіт (навіть PCIe вже 32 буде, хоча 64 на підході), і затримки на лінії обіцяють в 4 нс, що меньше ніж L3 кеш - навіщо тоді кеш - всі дані легше відправити в проц. Врешті решт як АМД зі своїми 2,3 млрд. на 2 канали памяті + куча ліній PCIe (+над ними IF паралельно для зовн. сокета) + ~150 ліній IF для 2 чіплетів + вн. хаб.
відеокарта - візьми буь-яку, проскануй затримку до її памяті - ~100 нс при прямих операціях (в FPGA 70 нс), і це через PCIe v3 11 року, а що при v5 буде.
в IBM кеш L4 прямо в проці, а не на зовні в контролерах памяті. кеш потрібен для всіх операцій, а не тільки для оперативи
ronemun
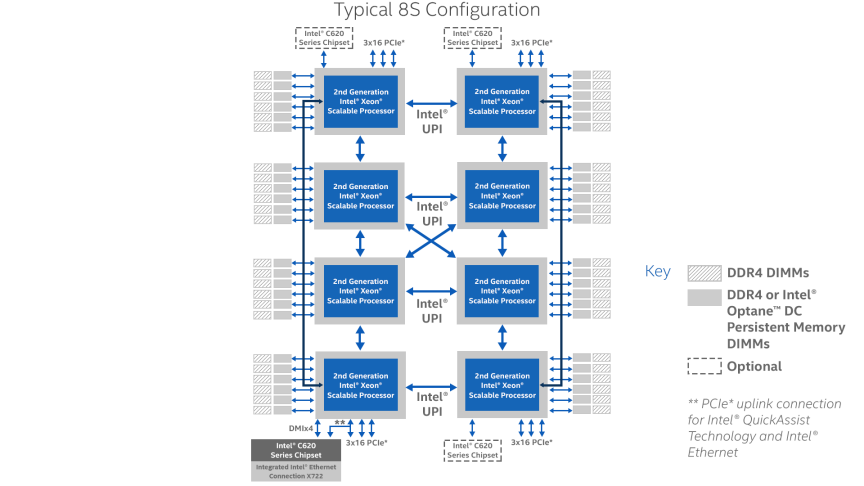
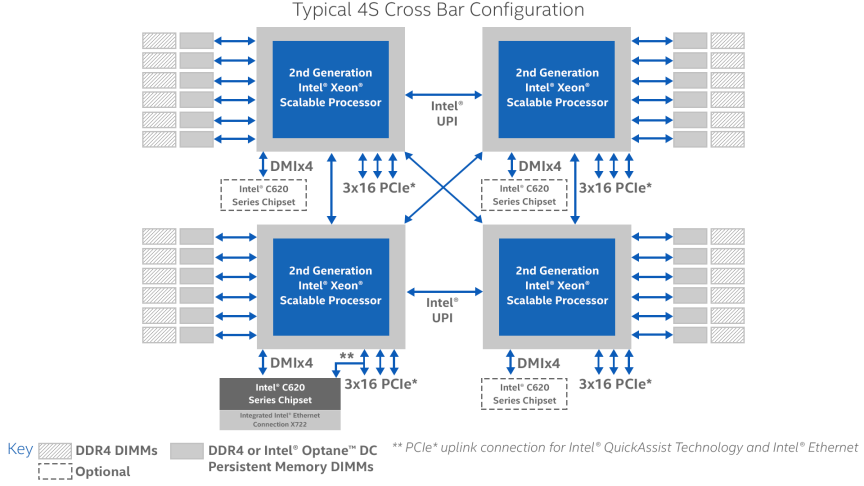
І всі ці Е7/платинуми нафіг нікому не потрібні тому, що софти, котрі так гарно вміють в нуму можна перелічити по одному пальцю однієї руки. Не потрібні настільки, що 8-сокетні рішення в масс маркет більше не випускає ні хіюлет, ні делл. Хьюлет для збочинців випускає супердом за реально мільйони золотом. Хоча ще років 6-7 тому їх намагались просовувати всі, кому тільки не лінь в самих звичайних серверах. Народ не оцінив. А процесори технічно все ще вміють в 8 сокетів без додаткових контролерів, і ті ж супердоми можуть бути до 32 сокети з контролерами UPI. Тільки наскільки мені відомо в Україні таких цяцьок рівно нуль. Навіть якщо хтось десь заникав і не показує нікому, то все одно погоди вони не роблять.
Тим часом 4-сокетні рішення теж присмерті по рівно тій же причині.
Востаннє редагувалось 02.03.2021 00:26 користувачем Scoffer, всього редагувалось 1 раз.
до чого 8 сокет - з них і 2 сокет роблять, і 4, і навіть 1, як Lenovo. Просто вони більше памяті тримають і, головне, швидкість памяті вища через те що меньші напряги на шину, оскільки сам контролер прямо біля оперативи, точніше на касеті з оперативою. Інакше як на платі розмістити 64-96 слотів. І оператива тоді дешевше обходиться - планки 32 значно дешевше за ГБ ніж 128.
І до чого тут нафіг 8 сокетів по 16 ядер =128 ядер чи 4 сокета по 28 = 112 - коли саме круто це АМД з її 2 по 64 = 128. І очевидно буде тільки більше а не навпаки. Той же IBM теж 4 сокета має і 8 потоків на ядро, ARM вже зараз 96-128 ядер на сокет.
Та й я не кажу зовнішній контролер для великої кількості ядер, а навіть для звичаних проців - просто щоб не вести таку величезну сітку дротів заради 1 каналу оперативи, коли це можна зробити значно ефективніше і корисніше - для всіх можливих пристроїв. Контролер памяті нічим не відрізняється від відяхи - то чому він в проці? Чому навіть сама тухла древня відяха маючи той же 128 біт контролер DDR3/GDDR3 навіть тоді не вважалась за щось цінне, а тут такий супер необхідний елемент
ronemun
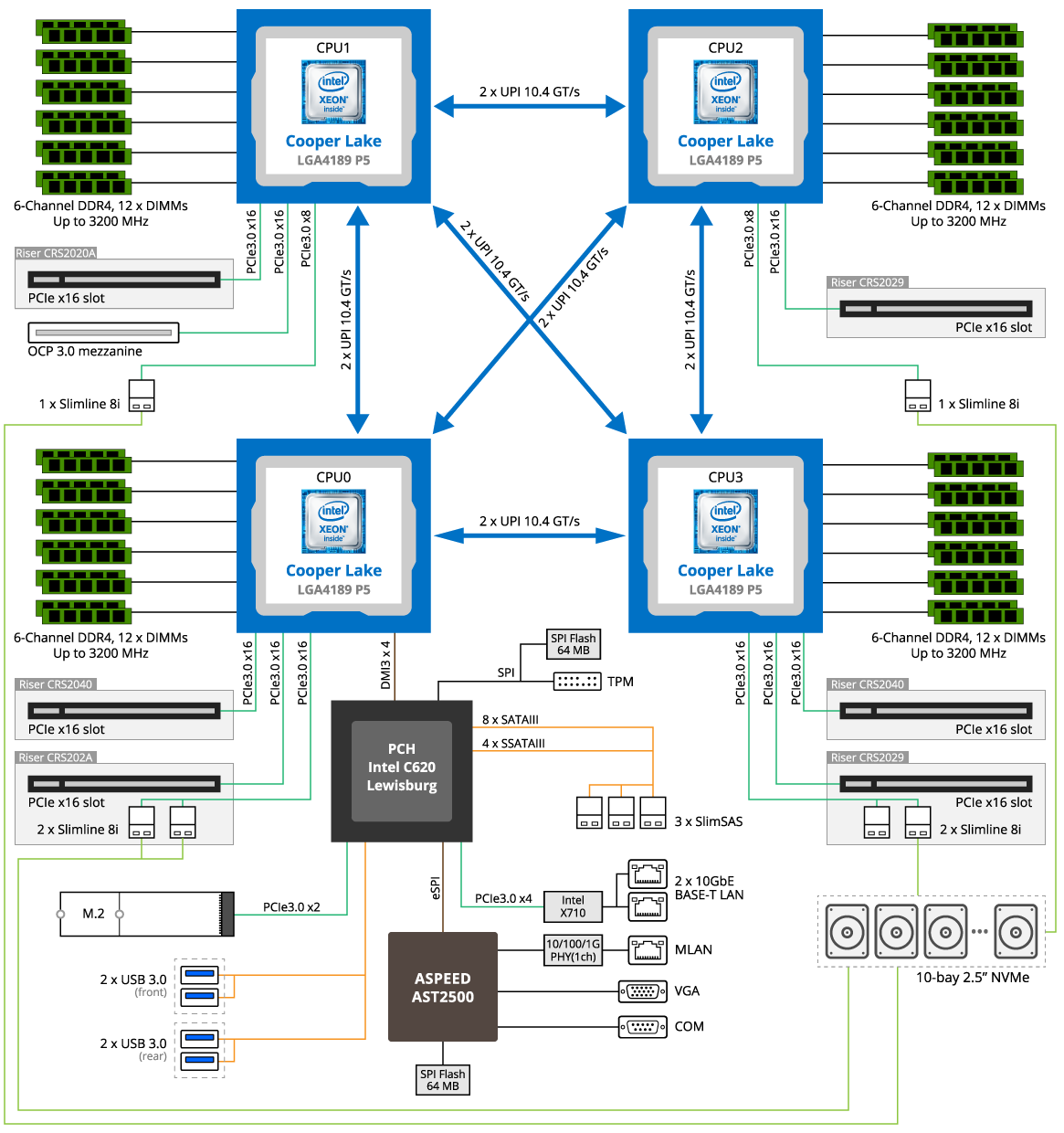
Немає ні в Е7 ні в платинумах ніяких зовнішніх контролерів оперативи. Ти щось плутаєш. Всі планки втикаються напряму в проц.
По 12 планок в один сокет максимум, що = 48 для 4 сокетів і 96 планок для 8 сокетів.
спойлер
Єдині доступні на ринку рішення з зовнішніми контролерами в окремих сокетах або прямо в планках пам'яті це рішення від IBM. IBM z i IBM Power відповідно. Обидва рішення з L4 кешами на контролерах.
так на твоїй же першій діаграмі показано Intel Scalable Memory interface 1 чіп на 2 канали памяті - це якраз і є ті контролери. В жоден E7 проц неможливо запхати оперативу напряму - хоча б тому що 6 каналів на 2011 сокеті тупо не влізуться, а в них ще й 4 зєднання QPI на проц. Це навіть в 1567 сокеті було - подивись на плати.
До того ж ці інтерфейси не просто так - це дозволяло поміняти плату з процами не змінюючи память - E7 v3 проци підтримували ddr3 память
Сам SMI це шина типу PCIe, по якій ідуть пакети з командами до памяті, і дані назад - тобто звичайна блочна шина. А контролер і інтерфейс DDR в чіпах